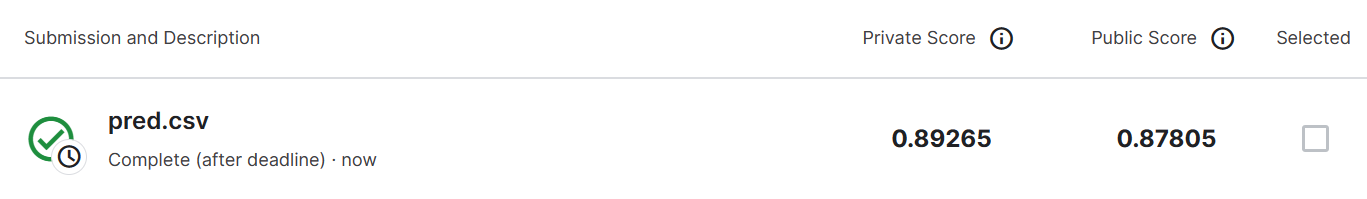一、Overview
[Kaggle竞赛地址](ML2021spring - hw3 | Kaggle)
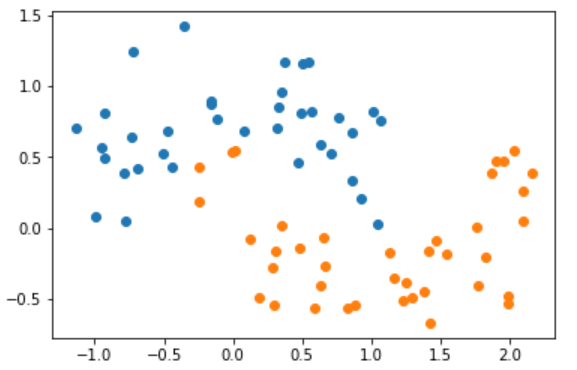
竞赛内容:根据食物图片进行分类(11分类)
训练数据格式:3190 张有标签数据,6786 张无标签数据,660张验证集数据
测试数据格式:3347 张
二、Strong Baseline
暂时没有过 StrongBaseline
修改模型
1
2# 如果使用预训练模型就能轻松过StrongBaseline了
model = torchvision.models.resnet18(pretrained=False).to(device)图像增广
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# 由于此次训练数据极少,图像增广就显得十分重要
# 经测试只进行简单的图像增广(翻转旋转)对结果没有很大的影响
# 所以此处使用较为复杂的transform来扩充测试集
train_tfm = transforms.Compose([
# Resize the image into a fixed shape (height = width = 128)
transforms.Resize((width, width)),
transforms.RandomChoice(
[transforms.AutoAugment(),
transforms.AutoAugment(transforms.AutoAugmentPolicy.CIFAR10),
transforms.AutoAugment(transforms.AutoAugmentPolicy.SVHN)]),
transforms.RandomHorizontalFlip(p = 0.5),
transforms.ColorJitter(brightness=0.5),
transforms.RandomAffine(degrees=20, translate=(0.2, 0.2), scale=(0.7, 1.3)),
transforms.ToTensor(),
])半监督学习
使用当前训练的模型给没有的标签的图像打上标签加入到训练集当中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43# 没有标签的图像是有标签图像的两倍有余,如果想要过 strong baseline,这些数据是必不可少的
# 训练刚开始的时候正确率太低不能直接开启半监督学习,否则会适得其反
# 当模型在验证集上的预测率达到70%时就启用半监督学习
def get_pseudo_labels(dataset, model, threshold=0.8):
# This functions generates pseudo-labels of a dataset using given model.
# It returns an instance of DatasetFolder containing images whose prediction confidences exceed a given threshold.
# You are NOT allowed to use any models trained on external data for pseudo-labeling.
device = "cuda" if torch.cuda.is_available() else "cpu"
# Construct a data loader.
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=False)
# Make sure the model is in eval mode.
model.eval()
# Define softmax function.
softmax = nn.Softmax(dim=-1)
idx = []
labels = []
# Iterate over the dataset by batches.
for i, batch in enumerate(data_loader):
img, _ = batch
# Forward the data
# Using torch.no_grad() accelerates the forward process.
with torch.no_grad():
logits = model(img.to(device))
# Obtain the probability distributions by applying softmax on logits.
probs = softmax(logits)
# ---------- TODO ----------
# Filter the data and construct a new dataset.
for j, x in enumerate(probs):
if(torch.max(x) >= threshold):
idx.append(i * batch_size + j)
labels.append(int(torch.argmax(x)))
# # Turn off the eval mode.
model.train()
dataset = PseudoDataset(Subset(dataset, idx), labels)
return dataset
已经train了500轮,距离 strong baseline 还差3%