一、多模态大模型的发展历程


二、多模态大模型的输入-输出空间

(1)视觉编码器架构

(2)离散化视觉表示

(3)视觉编码器训练策略


时间复杂度排序
$n^n, n!, 9999n^{99}, n^{100}$
输出a的值
1 | int a = 0; |
散列表
散列表是数据结构的重点,经常会出现在选择和大题中,这里我额外出一道双散列的题目吧。
表长为11,插入序列为45,72,54,28,99,83,66,67,散列函数为H(k)=k%11,再散列函数 Hi(k)= (H(k)+ i^2)%11,其中i为第i次冲突。插入完毕后,删除元素45。
(1) 画出散列表
(2) 查找成功的平均查找长度
(3) 查找失败的平均查找长度
(4) 装填因子
数据结构
第一章
1 | 时间复杂度是数据结构学习中的基础内容,虽然一般难度不高,但对同学们的细心和耐心要求较高。在学习和练习时,除了理解基本概念外,仔细审题是非常关键的一步。如果遇到难以理解的题目,建议同学不要急于求成,而是可以尝试在草稿纸上模拟程序的执行过程。通过一步一步地推演,不仅可以加深对题目逻辑的理解,还能更直观地掌握时间复杂度的变化规律。这样做不仅有助于提高解题的准确性,还能增强同学在编程中的整体思维能力。 |
第二章
1 | 这一章同学表现得非常出色!几乎全对,展现了扎实的基础知识。数组和链表虽然是数据结构中最基本的内容,但它们的重要性不可忽视。掌握好这两个结构,不仅能帮助你更好地理解后续学习中的栈、队列、树、图等复杂的数据结构,还能为构建高效的算法打下坚实的基础。希望你在接下来的学习中继续保持这种良好的势头,把每一个知识点都掌握扎实,为应对更高难度的内容做好充分准备。继续加油;) |
第三章
1 | 在解决栈和队列相关的题目时,必须仔细分析操作的顺序,这一点非常关键。具体来说,需要明确以下几点: |
第四章
1 | 题目不是很严谨 |
第五章
1 | 卡特兰数在考研范畴内一般只会有三种应用。 |

1 | 近年来408的趋势就是越来越难,体现在数据结构上就是,最开始几年代 |
第六章
1 | 邻接多重表和十字链表目前考频较低,但其实完全有可能出一道大题,将一个邻接多重表转为无向图,然后再在这个无向图上做文章,所以还是需要重视的。 |

第七章
1 | 在学习过程中,重点把握关键概念,避免在考试中不太可能涉及的内容上花费过多时间。例如,尽管红黑树的插入删除操作都在考研大纲中,但删除操作通常被认为是边缘知识点。这个操作较为复杂,而且在历年的考试中从未考过,更大概率考的是插入操作。因此,虽然了解删除操作有益,但不需要过多深入研究。 |
第八章
1 | 首先,恭喜雎同学顺利完成数据结构的学习阶段!接下来,你可以考虑将算法与操作系统这两门课程结合起来学习,因为它们之间有很强的关联性,可以互相补充。当然,如果你觉得合适,也可以单独开始学习计算机网络。 |
操作系统
第一章
1 | 1、 CPU从特定主存地址(ROM)开始读取指令,执行ROM中的引导程序,进行硬件自检,确定磁盘位置 |
第二章
1 | 本章核心内容相对简单,只需了解每种调度算法的基本作用即可应对考试题目。然而,对于可抢占式的调度算法,特别需要格外小心。在考试中,为了避免出错,建议画出甘特图以辅助分析。这不仅能帮助你直观地理解进程的执行顺序,还能有效减少因计算不当导致的错误。 |
第三章
1 | 1、 预处理 |
第四章
1 | 借着第十一题,我们来搞清楚链式分配的两种方式:隐式链接和显式链接。 |

第五章
1 | 在学习和复习这一章时,我们需要特别注意一些考试概念上的细节。在考研中,SCAN算法和LOOK算法通常不会被区分开来。换句话说,虽然考试题目中可能会提到SCAN或C-SCAN算法,但在回答这些题目时,同学应当按照LOOK或C-LOOK算法的原则来进行解答。 |
组成原理
第一章
1 | 1、 预处理 |
第二章
1 | 这一章的重点在于掌握IEEE浮点数表示的格式,这是考试中经常出现的考点,几乎每年都会有相关的选择题。特别要注意的是,特殊情况的表示方式以及短浮点数和长浮点数的格式区别,这些细节在考试中往往是出题的关键。为了帮助大家更好地理解和记忆这些内容,我专门整理了两张表格,供大家参考和复习。 |

第三章
1 | 这里需要稍微注意的是,虽然考试中很少涉及全相联映射的考题,但实际上,全相联映射是组相联映射的一种特殊情况——它的组数为1。因此,全相联映射的计算方法与组相联映射是一致的。 |
第四章
1 | 这一章在计算机组成原理中既是难点,也是考试的重点,大题几乎每年都会考察。在复习过程中,需要特别注意Inter和AT&T格式的区别,尤其是目的操作数和源操作数的位置顺序问题,搞清楚到底是哪个在前,哪个在后。 |
第五章
1 | 这一章可以说是计算机组成原理中最为复杂的一章,要求同学对指令执行过程有深入的理解。比如,在指令执行的过程中,同学需要明确何时进行访存操作,何时程序计数器(PC)递增等。这些知识点经常出现在大题中,成为考察同学掌握程度的重要内容。同学在学习过程中可以尝试将指令执行的过程图示化,将每个步骤以流程图的形式绘制出来,标注出在每一步中发生的具体操作,图示化的学习可以帮助你更直观地理解抽象概念。 |
第六章
1 | 这一章的内容虽然相对基础,但要求我们在审题时特别细致,尤其是在涉及多模块存储器的部分。多模块存储器的存取方式主要有两种:轮流启动和同时启动。本章的大题重点探讨的是轮流启动的方式,但同时启动的方式也是非常重要的。 |

第七章
1 | I/O设备这一章的学习重点主要包括以下几个方面: |
计网
第一章
1 | 计算机网络这门课相对来说是四门专业课中比较简单的一门,不过其中需要记忆的知识点仍然不少,尤其是一些计算公式和概念。当前咸鱼更新仅到第三章,进度相对较慢。如果有同学想继续学习后续章节的内容,推荐后续章节同学可以观看b站湖科大的视频,是湖科大的高老师讲的。高老师的授课内容条理清晰,逻辑严谨,能够帮助大家更好地理解这门课程的核心知识点。对于需要掌握的重点内容和复杂概念,视频中的讲解也十分到位。 |
第二章
1 | 关于以太网传输标准,给同学总结一下,因为考试可能并不会告诉同学具体的信息,而会直接采用100BaseT这种代号的形式。 |
语音转文本:
聊天交互:Qwen2
文本转语音:
表现形式:2d/3d模型
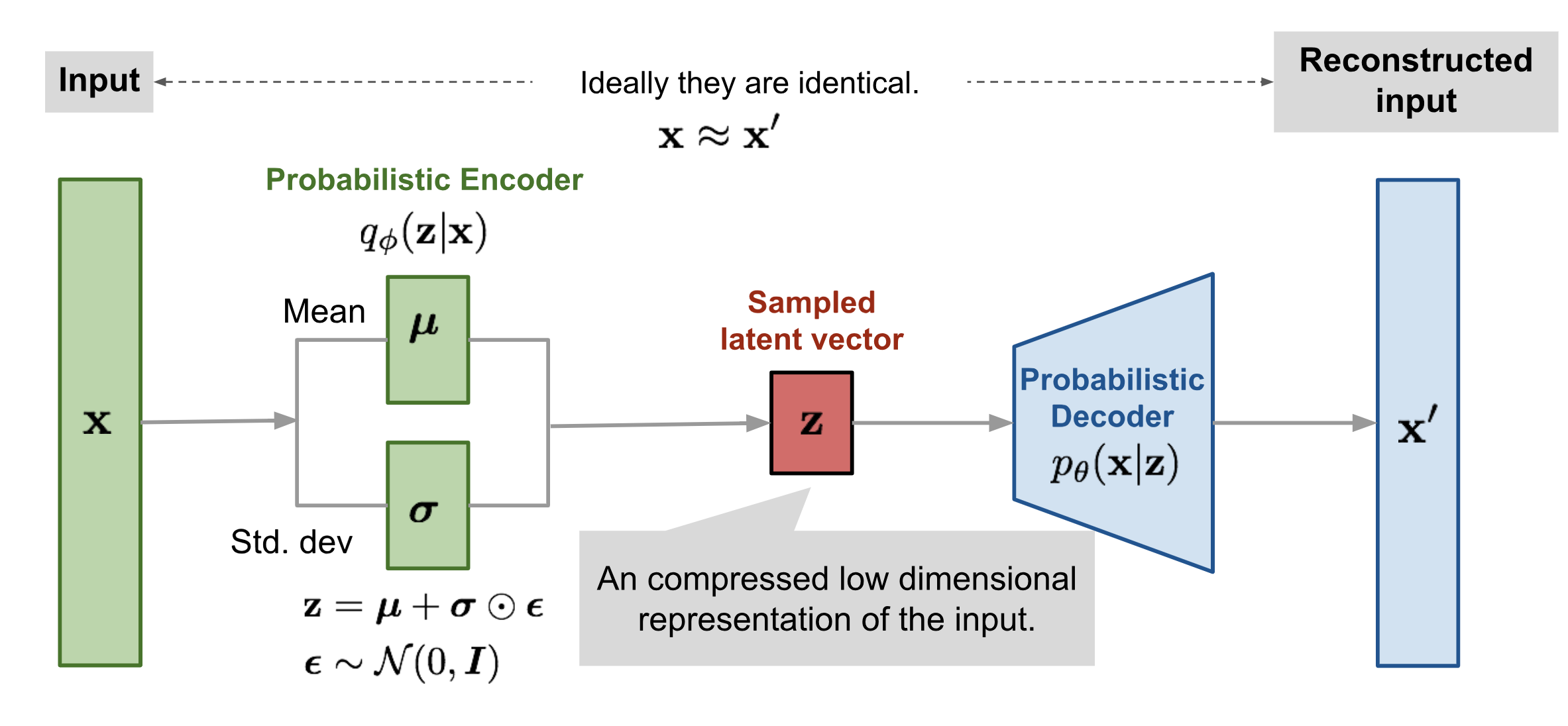
当我们想使用简单分布近似所观测到的数据分布时,KL 散度可以用于衡量在近似的过程中损失了多少信息。因此我们可以使用 KL 散度作为损失函数,从而学习到复杂数据的近似分布。
$$
D_{KL}(p||q) = \sum^N_{i=1}p(x_i)(logp(x_i)-logq(x_i))
$$
==KL 散度不能用于衡量两个分布之间的距离,因为 KL 散度不是对称的 ($$D_{KL}(p||q) != D_{KL}(q||p)$$)==
$$
L(θ,φ;x,z) = E_{z \sim q_φ(x|z)[logp_θ(x|z)]} + D_{KL}(q_φ(z|x)||p(z))\
L(θ,φ;x,z) = E_q[log(Decoder的输出分布)] + D_{KL}(Encoder的输出分布||预设的正太分布)\
L(θ,φ;x,z) = \frac{1}{m}\sum^m_{i=1}(x_i-\hat{x_i})^2 + D_{KL}(q_φ(z|x)||p(z))
$$
后半部分的KL 散度控制 Encoder 输出类正太分布,而前半部分的期望则是重构损失,用于衡量输入与输出的差异。在实际的代码编写中,一般使用MSE代替左半部分。
[Kaggle竞赛地址](ML2021Spring-hw2 | Kaggle)
竞赛内容:根据声音 frame 预测 phoneme 的类别(39分类问题)
训练数据格式:1229932 × 429,此处将前后五个frame连接在一起,可以更好地预测当前的类别
测试数据格式:451552 × 429
暂时没有过 StrongBaseline
训练集重采样
训练集类别之间数量差异极大,类别最高的数量可达178713,而最低的类别只有3883。在验证集上验证时这些低数据量的类别预测率普遍低于高数据量的样本,这里将每个类别数量都拓展到15000。修改后低数据量类别预测率显著提高,但总体预测率并未有明显提高,可能测试集中的低数据量类别的样本也同样少。
1 | train_class = [] |
增大网络模型
1 | class Classifier1(nn.Module): |
使用l2正则
1 | # l2正则即在loss中添加|w|^2,控制w的大小,求导后本质上等同于weight_decay |
后处理(提升明显)
音频信号是连续的,而frame的长度只有25ms,因此一个单词往往会对应多个frame,这些frame都是连续的且类别相同。
1 | # 11 3 11 -> 11 11 11 |

猜测要使用lstm,gru等语言类模型或训练多个模型进行ensemble