1. 多项式回归
最近高数刚复习到无穷级数这一章,里面提到了非常多的展开式,即用多项式去近似那些我们不容易求的函数,以此简化对实际复杂问题的计算,sinx 就是其中之一。
$$
\begin{gather*}
sinx = \sum\limits_{n=0}^\infty(-1)^n\frac{x^{2n+1}}{(2n+1)!}
\end{gather*}
$$
而今天的主角——多项式回归,有些类似于无穷级数。它是利用了多项式来拟合数据集做出预测,算是线性回归的增强版本,拟合曲线方程为 $y = \sum\limits_{i=0}^{m}\sum\limits_{j=0}^{m-i}W_{im+j}X_1^iX_2^j$(这里出于简便只给出了两个特征时的情况)。
2. 简单实现
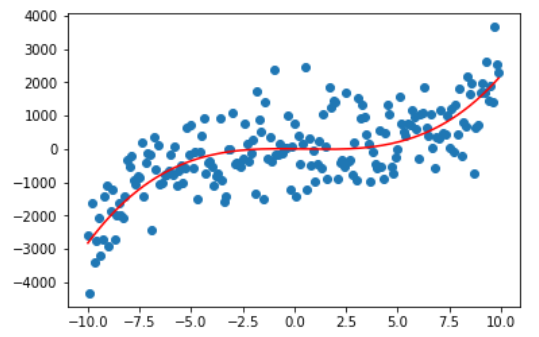
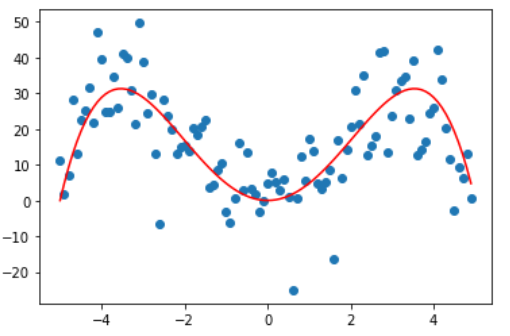
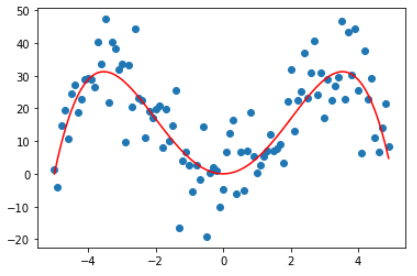
观察下图,这是一个由曲线 $y=2.6x^3-3.14x^2-8.8x$ 生成的数据集,当然是人为地加了些呈正态分布的噪声,红色为实际生成曲线。
1 | # 数据生成代码 |
对于这样的数据集,已知其最高次为三次,那我们可以直接设拟合曲线方程为 $y = w_1 * x^3 + w_2 * x^2 + w_3 * x + b$,采用梯度下降法来拟合曲线(梯度方向上变化率最大,往负梯度方向移动可以减少 y)。
==注:用预测值减去真实值 $w_1 * x^3 + w_2 * x^2 + w_3 * x + b - y^*$ 得到预测误差,将所有误差绝对值相加就成了损失函数(MAE)。==
1 | # 使用MSE作为损失函数 |
我们先对原始数据进行预处理,其实本质上还是线性回归,但这里我们将 x 的高次幂也当做额外特征进行运算,从单维特征拓展成了多维特征。
==还有个偏置b,所以多加了一列全1列。==
1 | X = x.reshape([-1, 1]) |
1 | initial_theta = np.zeros_like(X_b[1]) # 初始权重方便起见都设为0 |
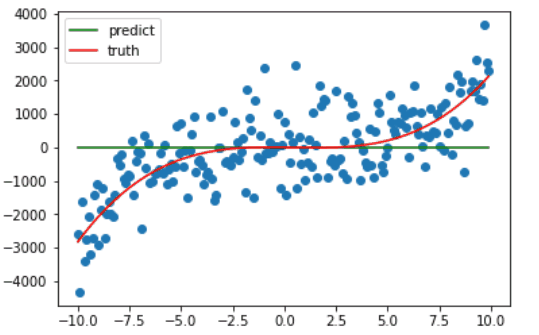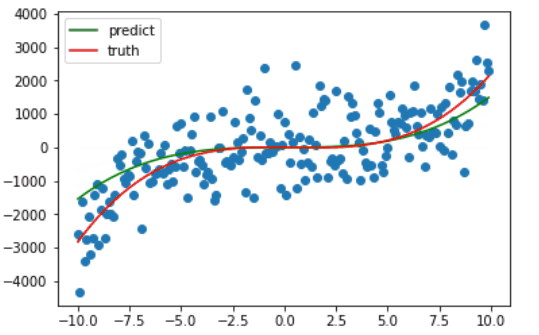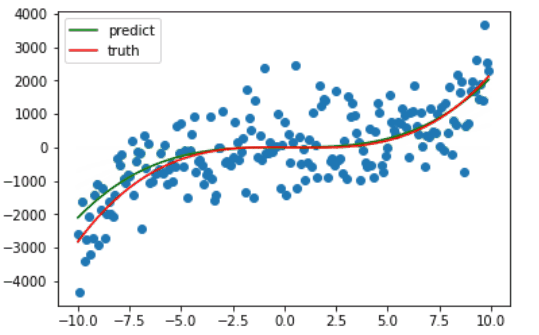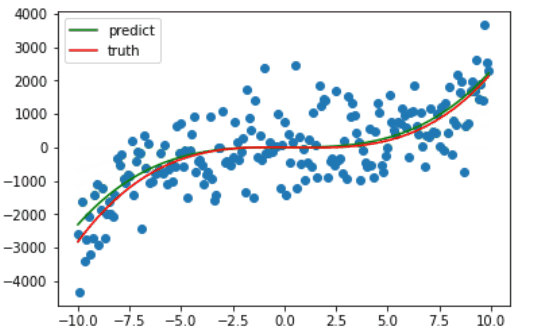
因为绘图比较费时,我只绘制了前十次梯度下降的过程,可以看出仅仅十次更新,训练的曲线已经和真正的曲线相差无几了。
最后在训练了 1e5 次后,系数最终被更新成 **[ 2.46963363 -2.44184783 -4.11097282 7.58382791]**,与原先设定的 [2.6 -3.14 -8.8 0] 差距不大,最后拟合完毕的曲线如下。
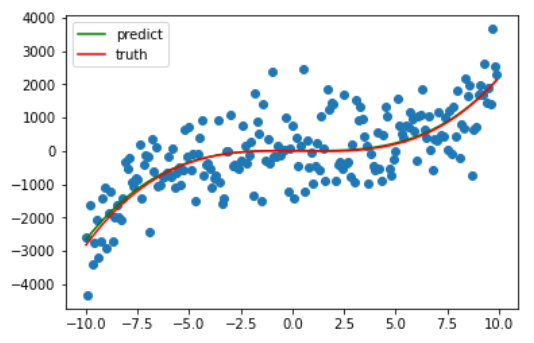
3. 多项式特征
在上述实现中,我们事先知道了这是个一元三次函数,因此将待拟合方程设成了一元三次方程的标准方程。但在正常情况下,我们不可能知道手头的数据集应该是一个几次的方程。所以这也就成为了我们在训练模型前需要额外设置的一个超参数。
而当存在多个初始特征时,多项式回归还能帮助我们寻找到特征之间的关联(这也是较线性回归增强的部分)。例如有两个特征 a 和 b,当次数为 3 时,多项式特征不仅把它们扩展成 $a^3$, $a^2$,$a$, $b^3$, $b^2$,$b$,还会添加这两个特征的组合,$a^2b$, $ab^2$ 和 $ab$。在初始特征 a 和 b 与 **y ** 看似没太大关系时,这些新增的特征反而更能体现与 y 的关系。
1 | # 生成多项式特征 |
测试
1 | X = np.arange(1,19, 1).reshape([-1, 3]) |
==注:n元m次会扩展到 $\frac{(n+d)!}{n!d!}$,这可比指数爆炸恐怖多了,组合爆炸!(还会产生其它问题,后面我们再讲)因此需要谨慎选择 degree 这个超参数。==
4. 封装成类
最后将上述代码封装成一个多项式回归的类。
1 | class PolynomialRegession: |
在上述实现中,新增了一个名为 standardization(均值方差归一化)的方法,这是因为多项式化采用了特征组合的方式,在 degree 很大时,例如 100,那么新增特征中的最高次就会是 100 次,这是一个十分恐怖的数,而最低次只是常数级,各个特征维度之间的跨度非常大!这就导致 eta 必须非常小,但凡稍大一点,高次项系数更新就会溢出,而过小的 eta 会导致低次项的系数根本更新不动(需要数以千万计次的更新)!
由此我们便加入了 standardization,在多项式化之后将各个特征放缩到均值为 0,方差为 1 的范围上来,把有量纲的表达式改成无量纲的表达式,将数据的所有特征都映射到一个统一的尺度下。
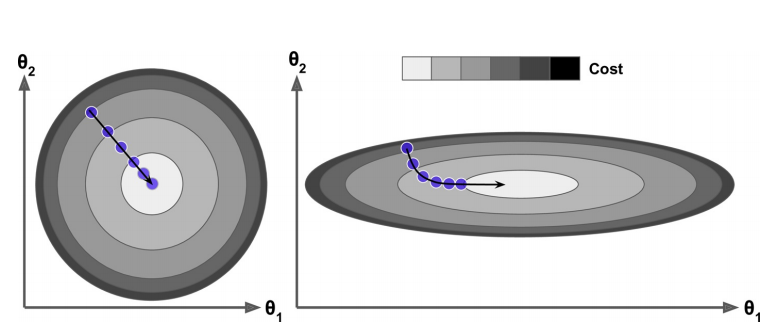
而且归一化后可以加速训练,**图 4.1 **左侧因为进行了归一化,因此等高线几乎是正圆,等高线上的法线指向圆心,因此能快速收敛到最小值,而右图没有进行归一化则需进行多次迭代。
==注:由于进行了归一化,我们的模型都是按照归一化的数据进行训练的,因此测试数据也要进行归一化,否则没有意义了。==
okay,下面让我们来测试一下这个多项式回归类!
1 | x = np.arange(-5, 5, 0.1) |
1 | pr = PolynomialRegession() |
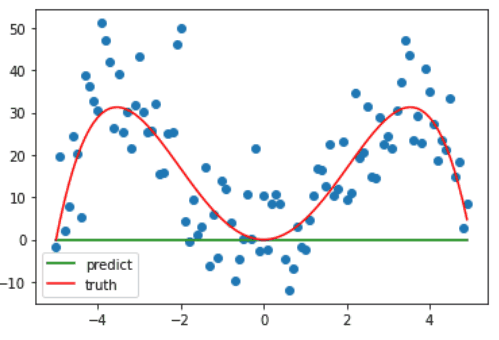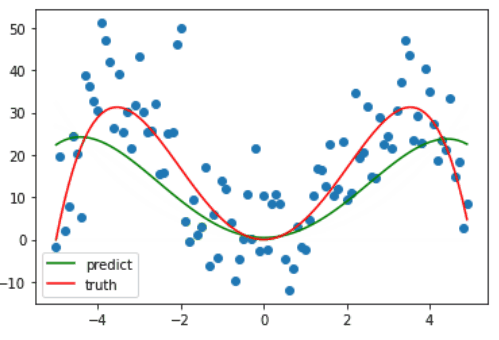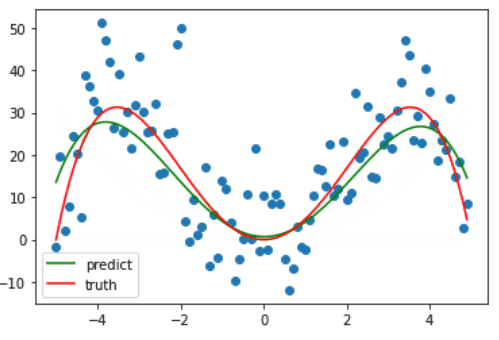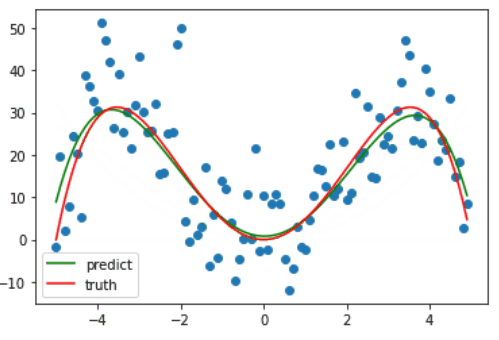
诶,那这个时候又有人要问了啊,诶虽然现在是拟合了数据集,但这不还是事先知道了这是个四个方程才设的多项式方程吗?嗯没错,接下来就看一下,如果 degree 取其它值会发生什么情况?
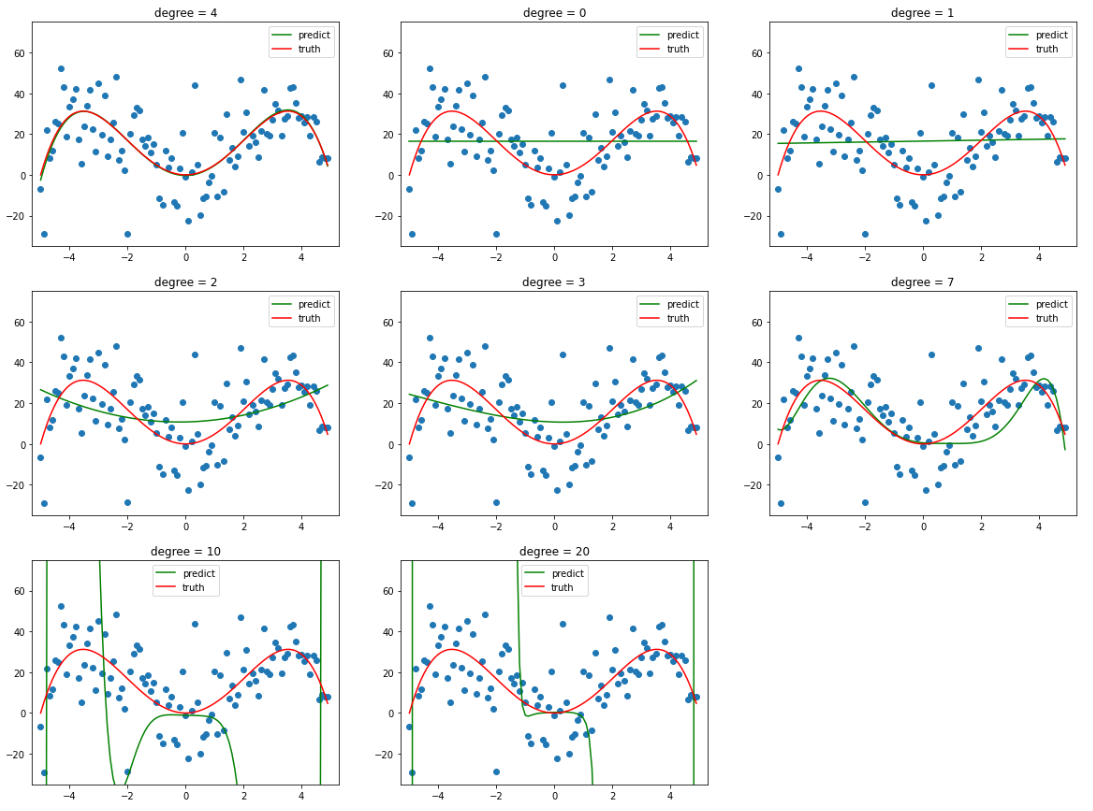
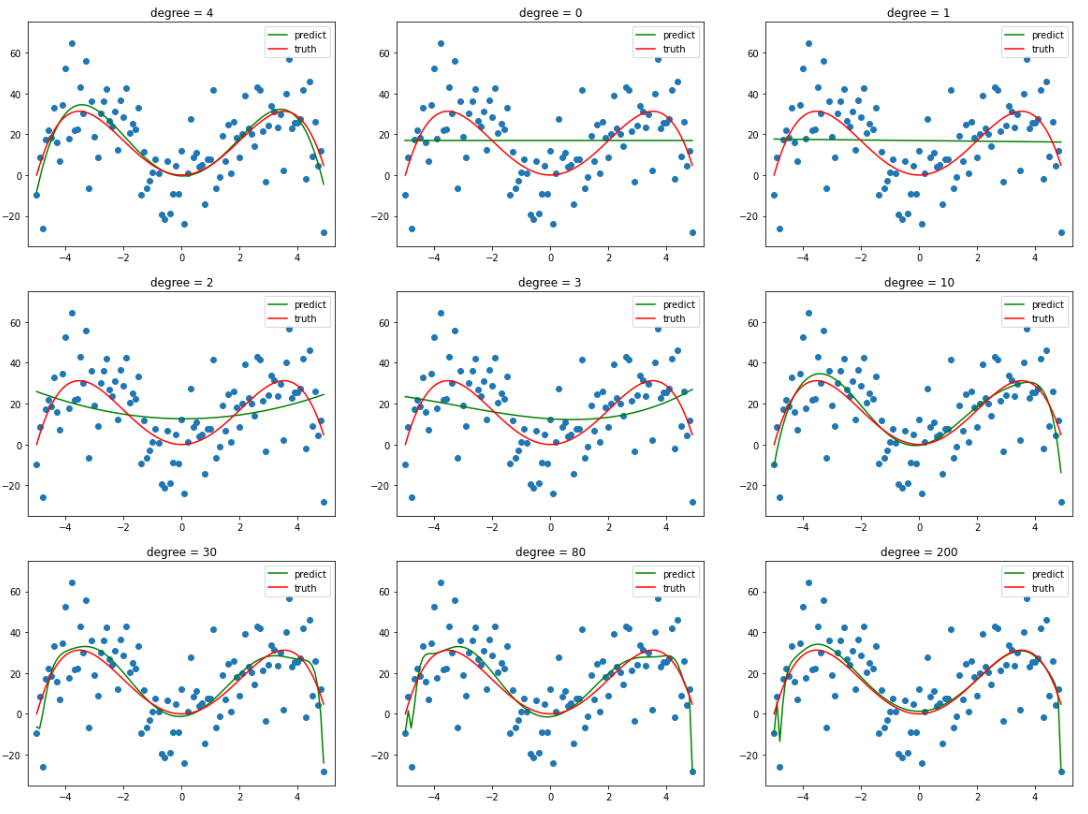
当 degree 较小时,其拟合曲线也较为简单,并不能很好地反映样本的趋势,也就是==欠拟合==。
而当 degree 逐渐增加时,其拟合的曲线便会更加 复杂,有更多的 “==弯==”,也就意味着当 degree 足够大时,其完全可以将整个样本给 “记住”,以达到在训练集上几乎百分百的预测率,这就是 ==过拟合==。但这根本不是我们所需要的!我们希望训练出来的模型不仅能在训练集上表现良好(当然喽),还要能对未来中那些没有见过的数据给出正确的预测,不然就是在自欺欺人罢了!
**图 4.4 ** 后面两张就是因为 eta 过小,训练不充分还没有完全拟合,看不出来过拟合的效果(PS:已经迭代 100W 次了,在往上耗时太长了)。
那么当给出训练集样本之外的数据时(这里训练集之外的样本指 [-100, 100] 的曲线),这些在训练集上表现 “貌似还不错” 的模型的表现又会怎么样呢?
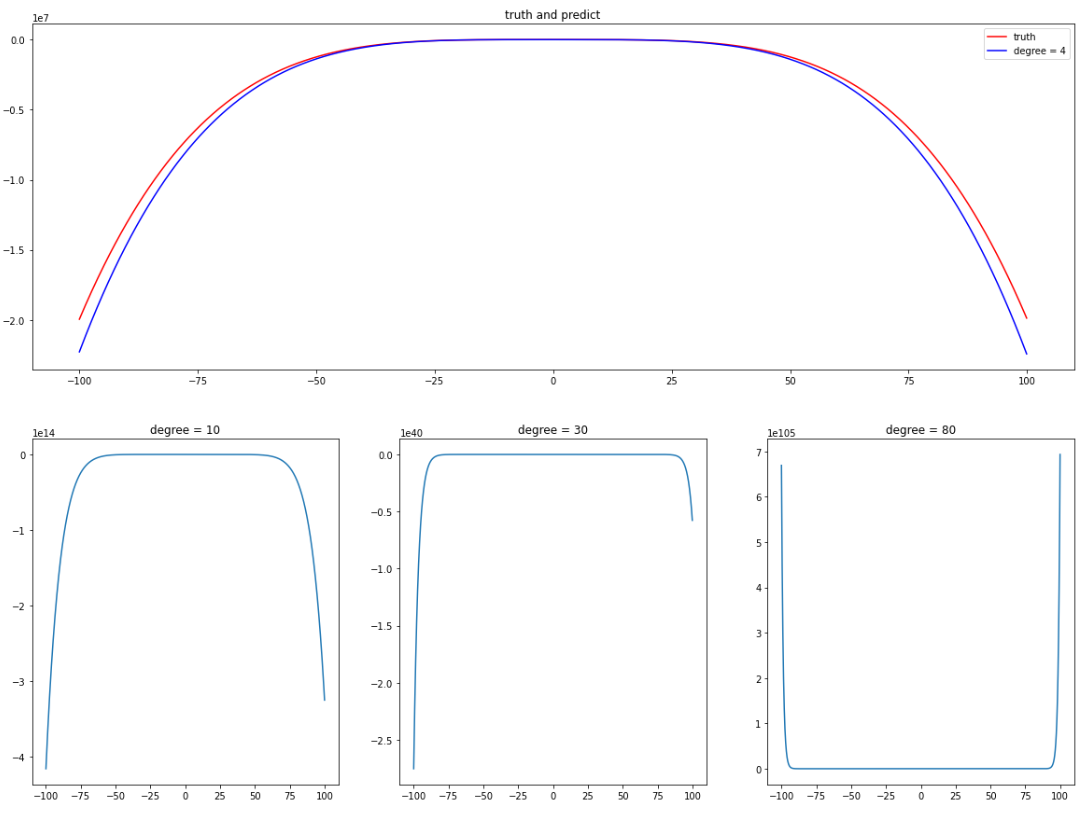
如 图 4.6,只有 degree = 4 时和原曲线还算是接近,其余的一个比一个离谱,degree 越大,误差越大。
至于如何减少过拟合呢,通俗来讲就是对模型进行==约束==。模型所拥有的 自由度 越少,那么其就越不会过拟合。
通常我们可以减少方程的 “容量”,交叉验证,dropout (不过在只有一层的传统机器学习中就相当于减少方程容量了)等,又或者是下面要介绍的正则化。
5. 正则化
正则化,一言以蔽之就是 限制 模型的 ==权重==,一般有 岭回归(L2),Lasso 回归(L1)和 **弹性网络 **等。
那么该怎么限制权重呢?很简单,把权重也一起加入到损失函数中就行了,这会迫使梯度下降在更新的时候不仅需要考虑如何让模型尽量拟合测试数据,还要考虑如何让权重尽可能地小。
5.1 岭回归
公式 5.1.1:岭回归损失函数
$$
\begin{equation*}
\begin{split}
Ridge(\theta)
& = loss(\theta) + \frac{\alpha}{2}\sum\limits_{i=1}^{n}\theta^2_i\
& = \frac{1}{m}(X\theta-y)^T(X\theta-y) + \frac{\alpha}{2}\theta^T\theta
\end{split}
\end{equation*}
$$
公式 5.1.2:岭回归导函数
$$
\begin{equation*}
\begin{split}
\frac{dRidge(\theta)}{d\theta}
& = \frac{dloss(\theta)}{d\theta} + \alpha\theta\
& = \frac{2}{m}X^T(X\theta-y) + \alpha\theta
\end{split}
\end{equation*}
$$
在 公式5.1中,不仅将权重加入到了损失函数中,还设置了一个超参数 α 用以调节正则化权重的==占比==。
当 α = 0 时,其就变为了普通的多项式回归,岭回归不会再起作用。α 越大,各特征的权重值就越小,体现在图像上则为曲线越光滑越平坦。当 **α -> $+\infty$**,为了使损失函数尽可能地小,梯度下降只能将权重尽可能地都更新为 0,也就变成了常值函数($y = \overline{y}$)。
因此 alpha 的取值还是比较考究的。
==注1:公式中 i 从 1 开始,即不包含偏置项,因为偏置项只用来调整曲线位置,并不会扭曲其图像。==
==注2:使用岭回归之前,一定一定要归一化数据!!!(血的教训)大多数正则化模型都对输入特征的缩放十分敏感!!!==
下面给出岭回归的部分代码实现,这里只给出了较多项式回归增加的部分,其余基本一致。
1 | class RidgeOfPolynomialRegession: |
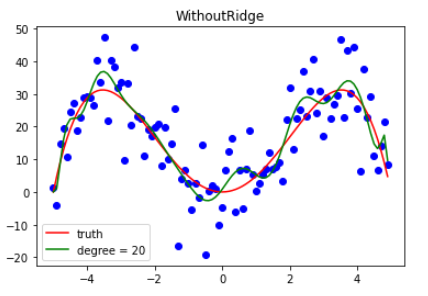
为了保证严谨,还是用的之前的样本,对比一下用了岭回归和没用岭回归的差别。
1 | x = np.arange(-1, 1, 0.15) |
如 图 5.2 所示,由于曲线次数比较高,导致表达能力过强了,会有一种曲线就是在把样本连起来的感觉,学习拟合变成了连线游戏。
1 | plt.plot(x, y2, c = 'red', label = "truth") |
而在加上岭回归之后,明显曲线就变光滑很多了,不是纯粹地只记住了样本,与原函数相比还是挺接近的,可以进行一定程度的预测。
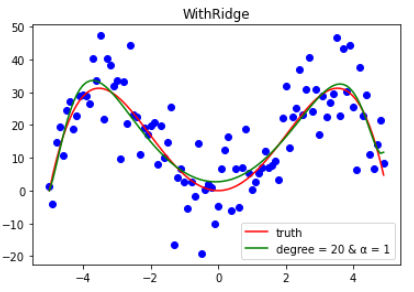
1 | plt.plot(x, y2, c = 'red', label = "truth") |
5.2 LASSO 回归
讲完岭回归之后,LASSO 回归就很简单了,全名 Least Absolute Shrinkage and Selection Operator Regression,中文名最小绝对收缩和选择算子回归。
与岭回归类似,只是新增项变成了 L1 范式 —— $\alpha\sum\limits_{i=1}^{n}|\theta_i|$。
公式 5.2.1:LASSO 回归损失函数
$$
\begin{equation*}
\begin{split}
LASSO(\theta)
& = f(\theta) + \alpha\sum\limits_{i=1}^{n}|\theta_i| \
& = \frac{1}{m}(X\theta-y)^T(X\theta-y) + \alpha\sum\limits_{i=1}^{n}|\theta_i|
\end{split}
\end{equation*}
$$
公式 5.2.2:LASSO 回归导函数
$$
\begin{equation*}
\begin{split}
\frac{dLASSO(\theta)}{d\theta}
& = \frac{dloss(\theta)}{d\theta} + \alpha sign(\theta)\
& = \frac{2}{m}X^T(X\theta-y) + \alpha sign(\theta)
\end{split}
\end{equation*}
$$
绝对值函数==在零点处不可导==同时也是极小值,因此要手动让其等于 0。而函数值大于 0 时导数为 1,小于 0 时为 -1,这不就是符号函数(sign)了嘛。
LASSO 的新增代码。
1 | class LASSOOfPolynomialRegession: |
同岭回归类似,下面只给出拟合结果。
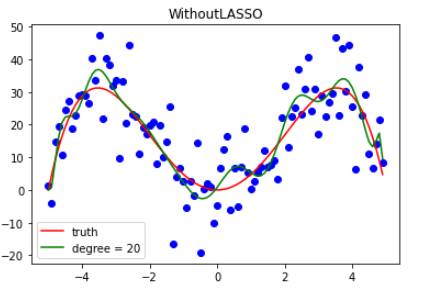
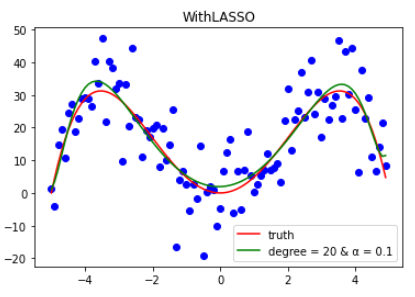
5.3 对比
既然岭回归和 LASSO 回归都是通过正则化来降低过拟合,那么它们两个有什么区别呢?
答:区别是肯定有的,请看下面两张图。(α 为[0.1, 1, 5, 10, 20])
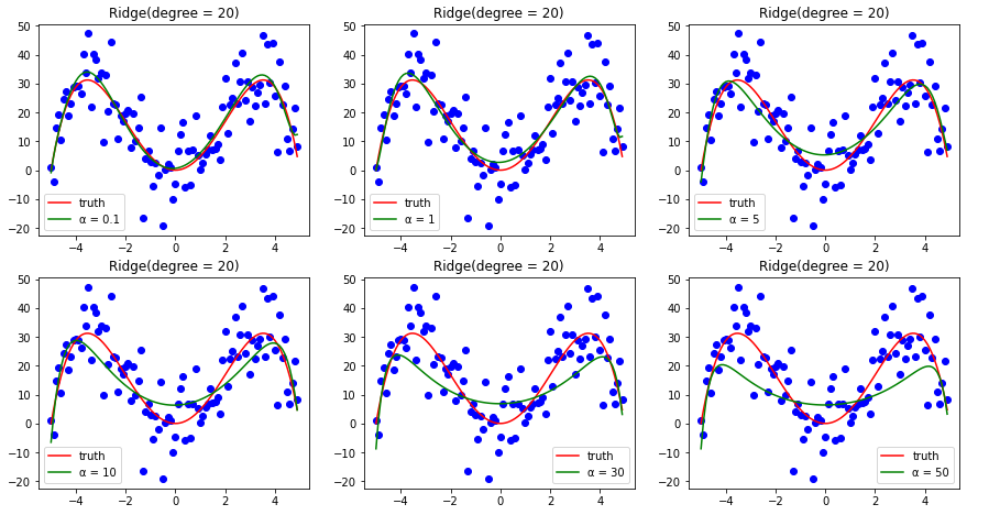
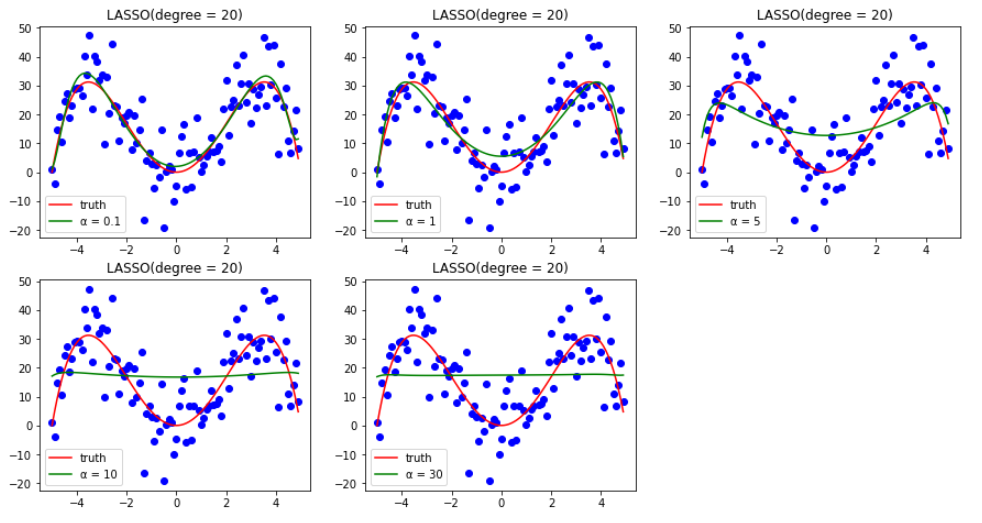
通过上两张图可以发现,在 α 逐渐增大时,二者的表现还是有所不同的。岭回归会越来越==平坦==(但始终还是曲线),而 LASSO 回归则会越来越==直==。
首先,α 越大,损失函数中关于参数权重正则化的那部分比重也就越大,由此我们可以忽略前面的 MSE。
岭回归的导函数也就可以近似为 αθ,同理 LASSO 回归也可以近似为 **sign(θ)**。
sign(θ) 只有三个值:-1, 1, 0。因此只能按照非常规则的方式更新,而在这个过程中就会有一些权重值提前来到零点,反映在图像上就会越来越接近直线。这也是它名字的由来——==选择算子回归==,将没用的特征权重设为零(当然也可能是有用的),留下另一些特征。
αθ 则会根据每个特征赋予不同权重更新,如 **图 5.3.4 **更新轨迹呈一个曲线型,权重一般不会更新成 0,反映在图像上也就会越来越平坦,像==山岭==一样。
5.4 弹性网络
弹性网络 将上述两个正则化结合在了一起,算是进行了折中。
公式 5.4.1:弹性网络损失函数
$$
\begin{equation*}
\begin{split}
LASSO(\theta)
& = f(\theta) + r\alpha\sum\limits_{i=1}^{n}|\theta_i| + \frac{1-r}{2}\alpha\sum\limits^n_{i=1}\theta_i^2\
& = \frac{1}{m}(X\theta-y)^T(X\theta-y) + r\alpha\sum\limits_{i=1}^{n}|\theta_i| + \frac{1-r}{2}\alpha\sum\limits^n_{i=1}\theta_i^2
\end{split}
\end{equation*}
$$
弹性网络 新增了一个超参数 r,而 α 的含义仍旧没变。我们可以通过调节 r 来控制 LASSO 与 Ridge 的==混合比==。
当 r = 1 时,该弹性网络等效于 LASSO 回归;当 r = 0 时,该弹性网络等效于 岭回归。