Dijkstra
Dijkstra 算法可以解决从一点出发,到所有其它点的最短路径问题,但只可用于没有负权重的图,这是一个基于贪心,广搜以及动态规划的算法。
要点
每次从==未求出最短路径的节点==中取出距离起点最近的节点,然后以这个节点为桥梁向外拓展,求出新的最短路径。
举例如下,要求以 A 为原点,到其他点的最短路径。
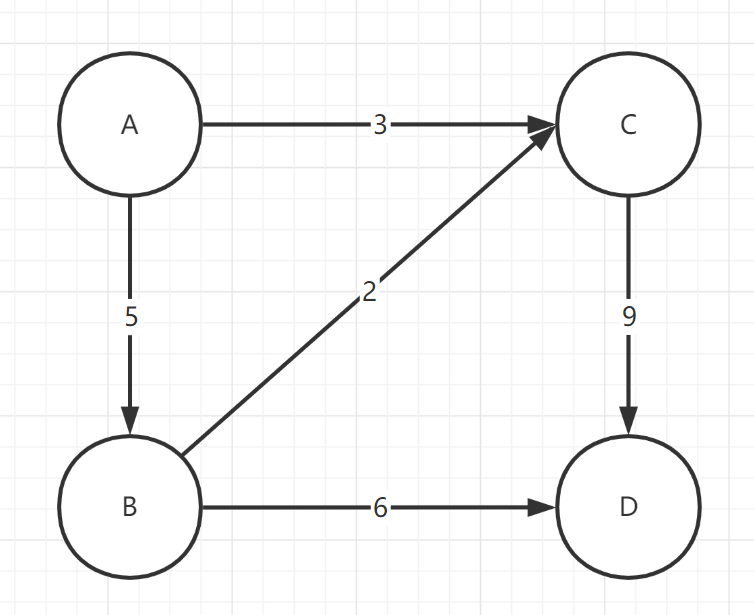
- result:已求出最小路径的顶点
- notFound:为求出最小路径的顶点
开始时,result = {A(0)},notFound = {B(5),C(3),D($\infty$)},然后从 notFound 中选取 C 点,刷新 result = {A(0),C(3)}, notFound = {B(5),D(12)},以此类推。
时间复杂度:$O(n^2)$
空间复杂度:$O(n^2)$
证明
但是这个算法为什么是正确的呢?这里就简单证明一下。
在那儿之前,先来看看这样一道题:我们规定因数中只含2,3,5(当然也包括1和本身)的数为 α 数,请按顺序输出前 n 个α 数。
解题思路:建立一个小根堆,一开始往其中压入 1,之后每次从堆中弹出一个数 x 并输出(==注意去重==),并压入 2x,3x,5x,直到弹出 n 个数为止。
很好理解,排在后面的 α 数必然是由排在前面的数,或是乘2,或是乘3,或是乘5所得,而 1 满足 α 数的条件,其乘以 2,3,5 所产生的数也必然满足 α 数,再加上有小根堆的堆化排序,每次弹出的数就是下一个 α 数。
再回到 Dijkstra 这个问题中来,一条最短路径一定是由另一条最短路径拓展得来,假使 A -> D -> B -> C 是 A -> C 的最短路径,那么 A -> D -> B 一定是 A -> B 的最短路径,可以用反证法来证明,如果存在一条路径 A -> X -> B 使得 A -> B 路径最短,那么 A -> D -> B -> C 就不是 A -> C 的最短路径,而是 A -> X -> B -> C 了。
一开始我们只有 A -> A = 0 这一条路径,借此拓展其他路径,在从这众多路径中选取距离原点最短的路径,这条路径就是最短路径,因为==非负权重==使得不可能再从其它点折返回来使得路径更低。
时间优化
先前提到过了,该算法的时间复杂度为 $O(n^2)$,每次选取一条最短路径,一共要选 n-1 次,而最短路径的经典做法的选取代价是 $O(n)$ ,但我们可以使用小根堆来优化这个过程,将选取最短路径的代价降低到 $O(logn)$,从而使得整体的时间复杂度为 $O(nlogn)$。
空间优化
采用邻接矩阵存储图的方式需要构建 $n *n$ 的矩阵,因此空间复杂度为 $O(n^2)$,但平方级别的代码,如果顶点数超过了 $10^4$,很容易 Out Of Memory,这时就可以使用==链式前向星存图==的方式,虽然名字中带有链式二字,但为了运行速度采用了数组的存储方式,不过思想还是链表。
假设共有 n 个点,m 条边。
具体做法呢,需要开辟四个数组,head[n], to[m], next[m] 和 weight[m]。
**head[n]**:存放以 i 为起点的第一条边的下标。
**to[m]**:第 i 条边所指向的节点。
**next[m]**:第 i 条边的下一条边的下标。(起点相同)
**weight[m]**:第 i 条边的权重。
在读入数据时需要填入上述四个数组中。
1 | int cnt = 0; |
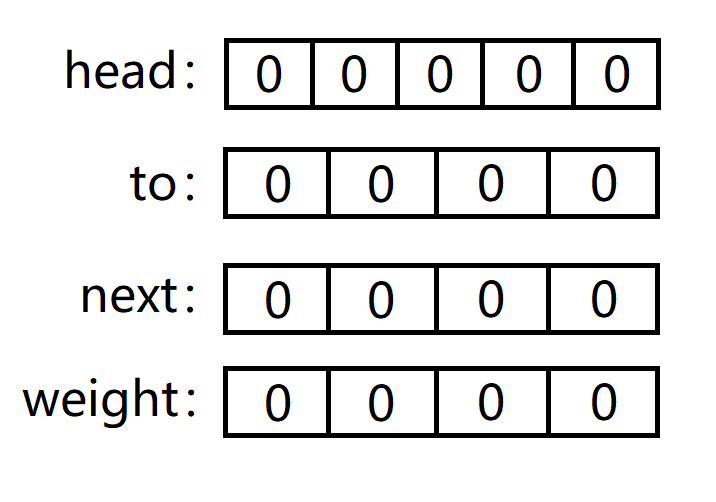
举个具体的例子,n = 4, m = 3。
数组初始化如下,head[n] 中的 0 不像其他三个数组,是有意义的,代表了没有以 i 开头的边的信息,这也是后面更新路径跳出循环的判断条件。
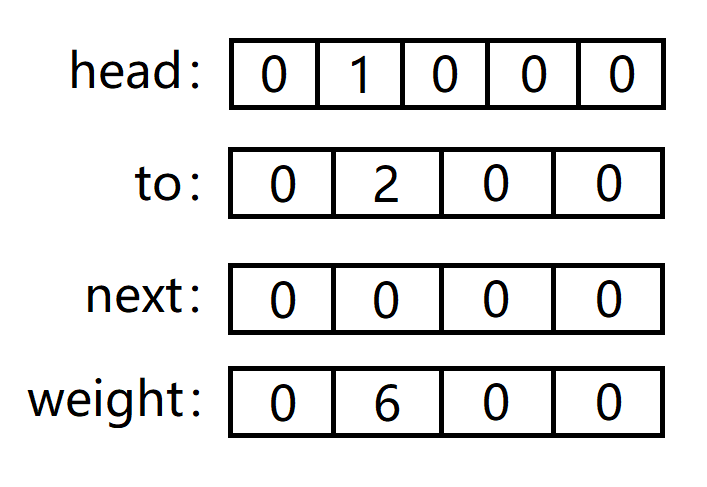
第一条边:1 -> 2 = 6。
to[1] = 2 和 weight[1] = 6:分别代表了第一条边的终点以及权重。
head[1] = 1:代表以节点 1 为起点的第一条边是所有边中的第一条边。
next[1] = 0:代表第一条边的下一条边是第 0 条边,也就是没有下一条边。
第二条边:3 -> 2 = 4。
to[2] = 2 和 weight[2] = 4:分别代表了第二条边的终点以及权重。
head[3] = 2:代表以节点 3 为起点的第一条边是所有边中的第二条边。
next[2] = 0:代表第二条边的下一条边是第 0 条边,也就是没有下一条边。
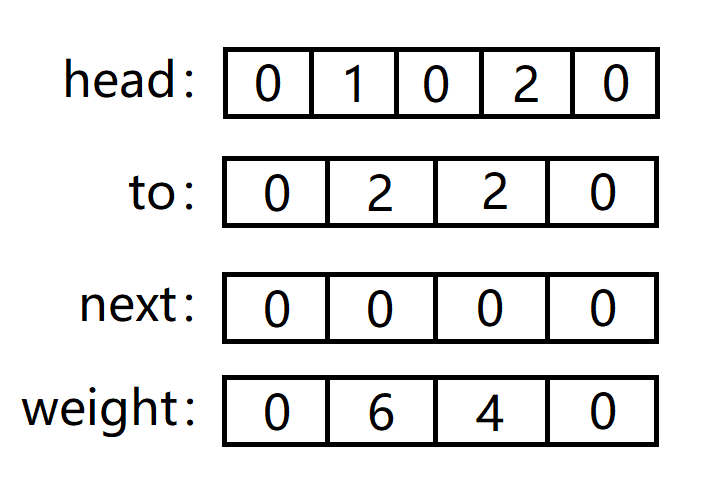
第三条边:1 -> 4 = 3。
to[3] = 4 和 weight[3] = 3:分别代表了第三条边的终点以及权重。
head[1] = 3:代表以节点 1 为起点的第一条边是所有边中的第三条边,被覆盖的边的信息需要先存储到 next 中,不然就丢失了,也就是将这条边的下一条边指向原先以 1 为起点的第一条边,类似链表的头插法。
next[3] = 1:代表第三条边的下一条边是第 1 条边。
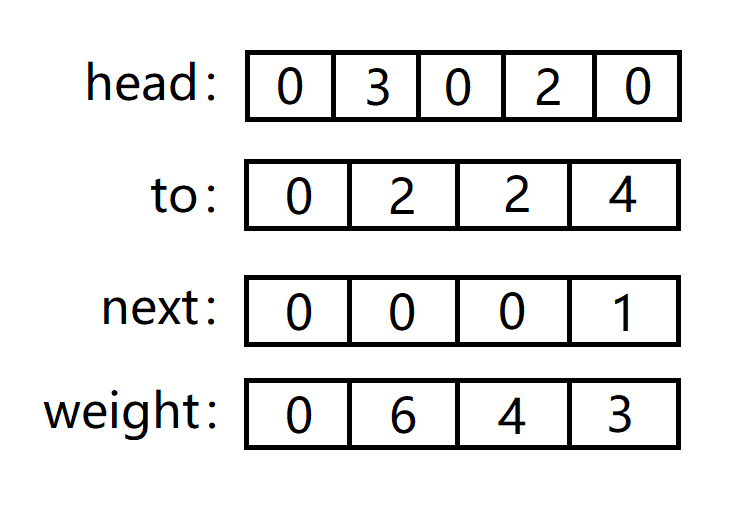
那么该如何访问以某个节点为起点的边呢?这里我们举例以 1 为起点的边。
head 中存储了以 i 为起点的第一条边,因此 head[1] 就是起始位置,而下一条边就是 **next[head[1]]**。
1 | for (int i = head[start]; i != 0; i = next[i]) { |
虽然说这样我们就无法用 $O(1)$ 的代价去找到某一条边,但在 Dijkstra 中我们并没有这样的需求,甚至其还帮我们过滤掉了不可达的点。
空间复杂度:$O(m + n)$
==注:如果存储无向边需要多开一倍的空间。==
代码
1 | import java.io.*; |