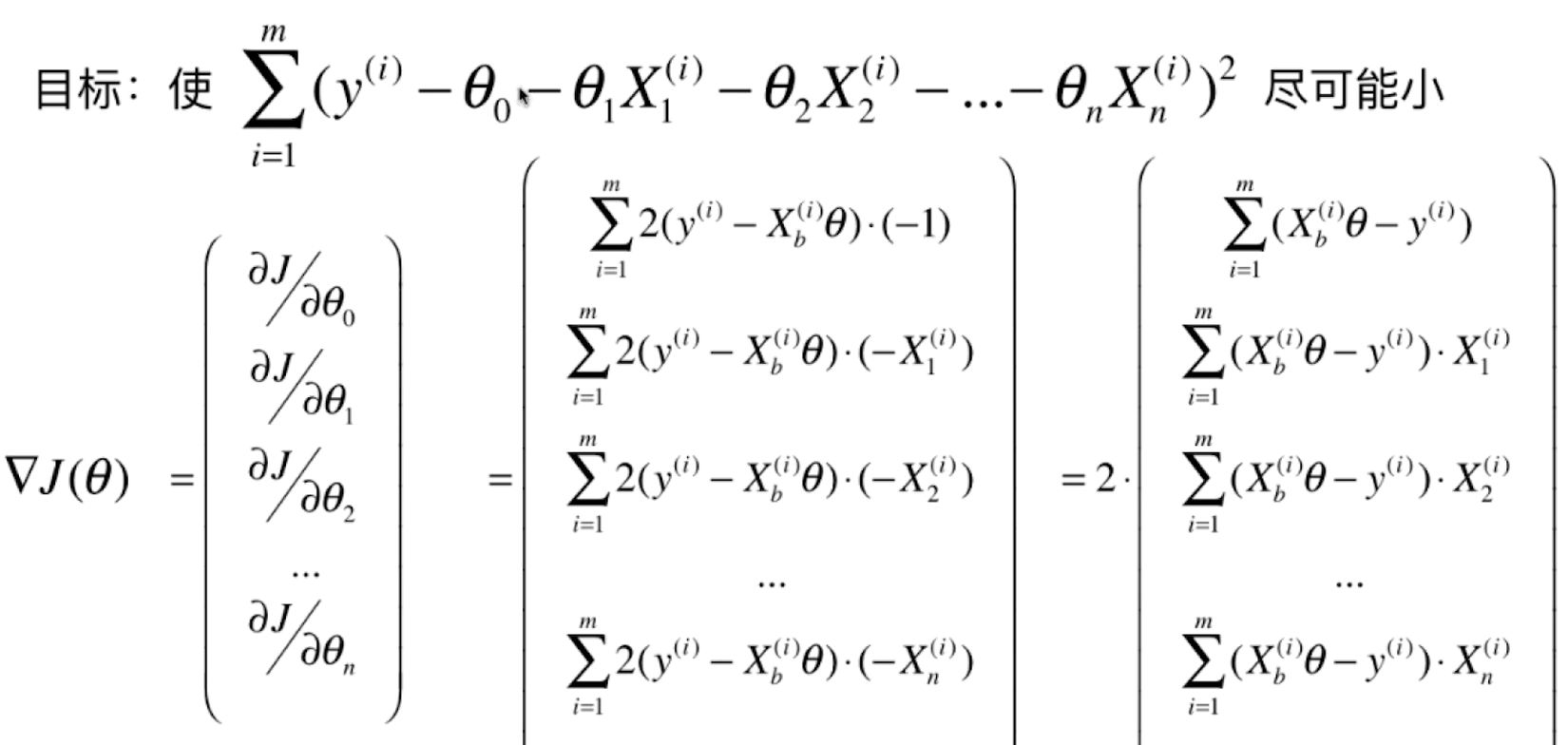import numpy as np import matplotlib.pyplot as plt
x = np.arange(-10, 10, 0.2).reshape([100,1]) y = 3.5 * x + np.random.normal(0, 20, 100).reshape([100,1])
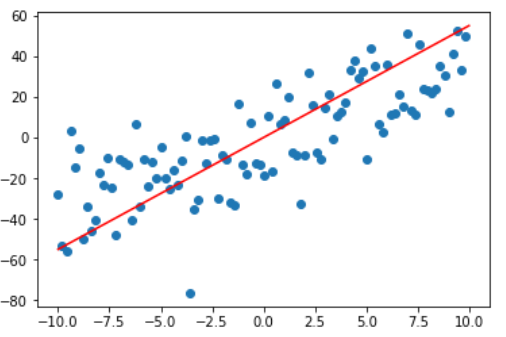
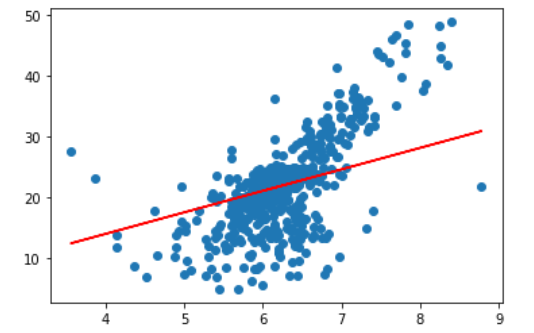
plt.scatter(x,y) plt.plot([-10, 10],[-55, 55], color = "red")
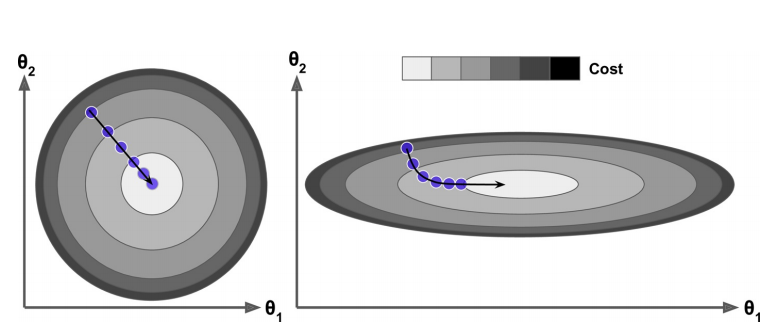
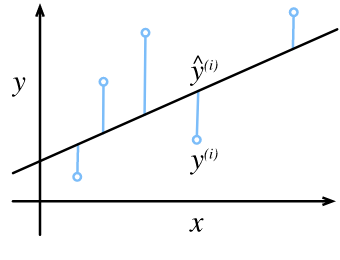
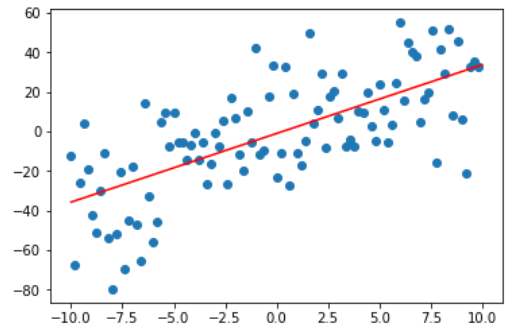
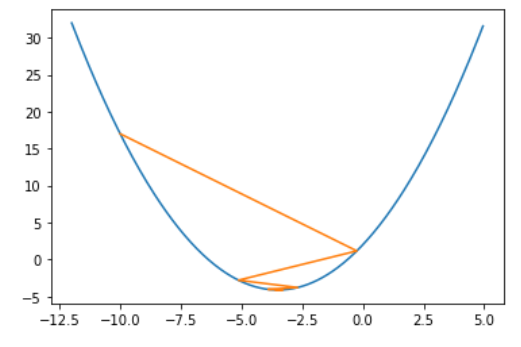
如上图所示,蓝色的离散点就是我们的测试数据,红色是要求的拟合曲线,方程为$y = ax + b$。
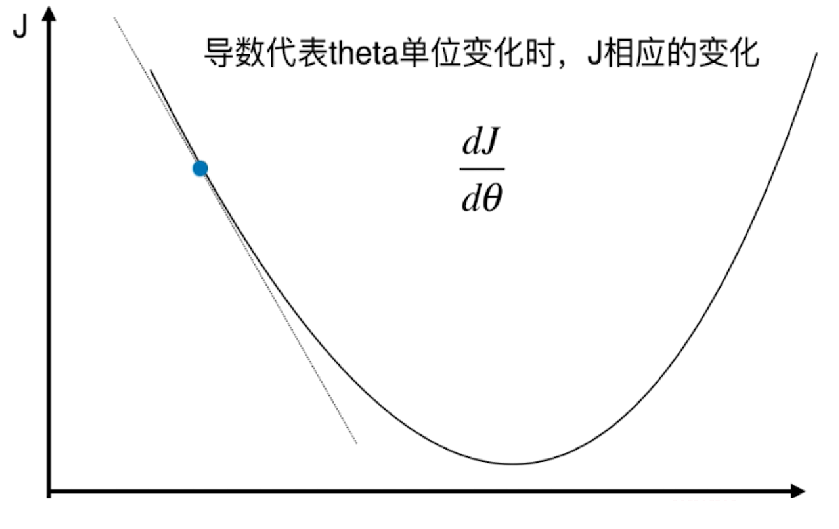
我们需要让这条直线的预测值和真实值的误差尽可能小,因此成本函数为
$cost = \frac{1}{m}\sum\limits_{n=1}^{m} (ax_n + b - y_n)^2$ (MSE)
此处$x_n$和$y_n$都是已知的数据,a和b才是我们要求的未知数。
该成本函数的偏导函数为
$\frac{dcost}{da} = \frac{2}{m}\sum\limits_{n=1}^{m} x_n(ax_n + b - y_n)$
$\frac{dcost}{db} = \frac{2}{m}\sum\limits_{n=1}^{m} (ax_n + b - y_n)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
defJ(a, b, x, y): return1/len(x) * np.sum((a * x + b - y) ** 2)
defDJ_a(a, b, x, y): return2 / len(x) * np.sum(x * (a * x + b - y))
defDJ_b(a, b, x, y): return2 / len(x) * np.sum(a * x + b - y)
defgradient_descent(a, b, eta, epsilon = 1e-6): i_iter = 0 whileTrue: last_a = a last_b = b a = a - eta * DJ_a(a, b, x, y) b = b - eta * DJ_b(a, b, x, y) if np.abs(J(last_a, last_b, x, y) - J(a, b, x, y)) < epsilon: break return a, b
1 2 3 4 5 6 7 8 9 10
a = 0 b = 0 eta = 0.02 epsilon = 1e-6
a, b = gradient_descent(a, b, eta, epsilon)
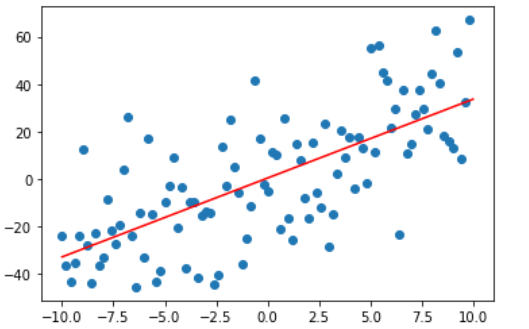
plt.plot([-10, 10],[-10 * a + b, 10 * a + b], color = "red") plt.scatter(x,y) plt.show()
效果也是挺不错的,不过这是一元的情况,可以写两个DJ_a和DJ_b,但如果是百元呢?
下面将会实现一种通用的梯度下降法。
先更改一下我们的成本函数,其中θ是系数矩阵,对于一元函数,它的shape就是(2, ),x需要再添一列(数值为1),这样x * a + 1 * b就正好是我们的直线方程预测值。