Amadeus
一、执行流程
语音转文本:
- 语音情绪识别:emotion2vec
- 语音识别:Whisper
聊天交互:Qwen2
文本转语音:
- 文本情绪识别:BERT
- 语音生成:GPT-SoVITS
表现形式:2d/3d模型
一、 VITS
1. VAE
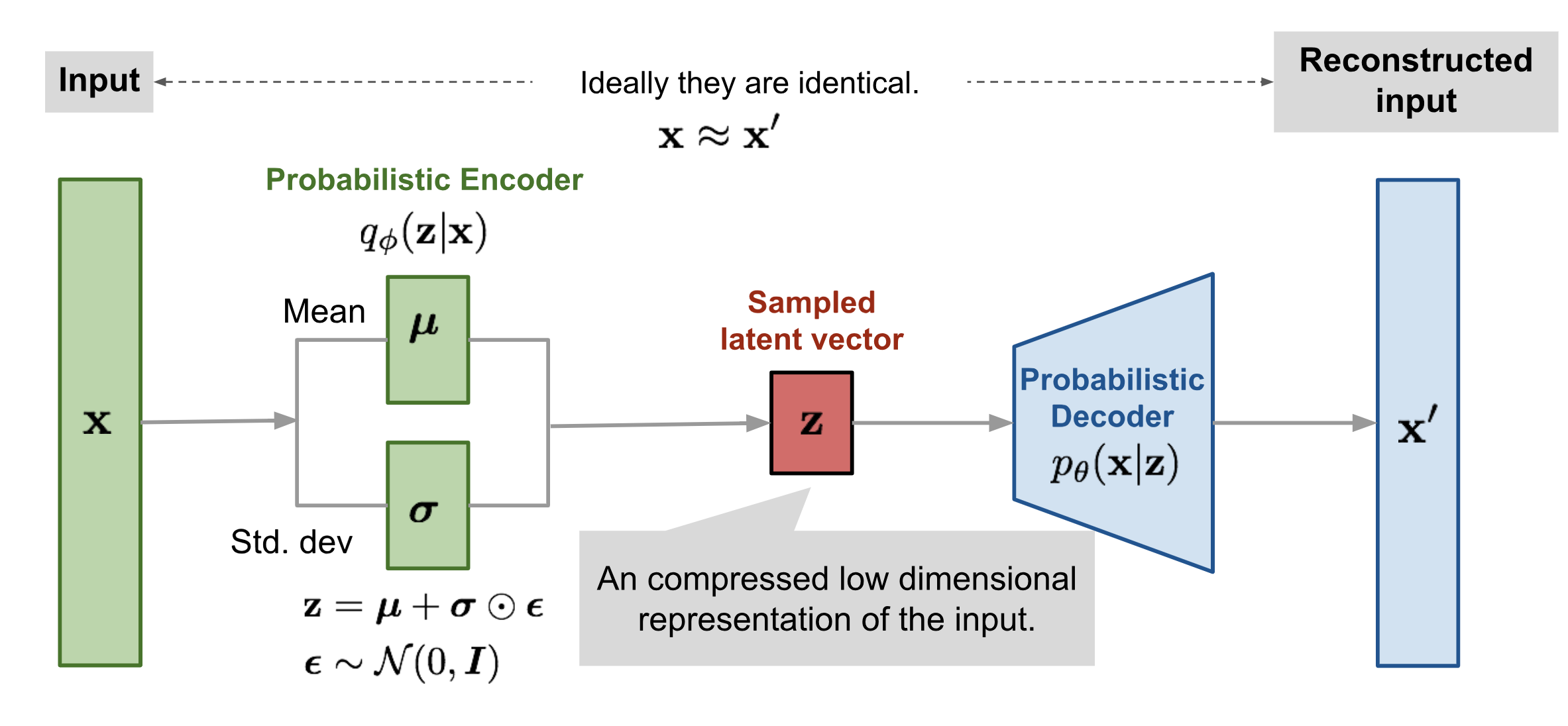
- KL 散度
当我们想使用简单分布近似所观测到的数据分布时,KL 散度可以用于衡量在近似的过程中损失了多少信息。因此我们可以使用 KL 散度作为损失函数,从而学习到复杂数据的近似分布。
$$
D_{KL}(p||q) = \sum^N_{i=1}p(x_i)(logp(x_i)-logq(x_i))
$$
==KL 散度不能用于衡量两个分布之间的距离,因为 KL 散度不是对称的 ($$D_{KL}(p||q) != D_{KL}(q||p)$$)==
- 损失函数
$$
L(θ,φ;x,z) = E_{z \sim q_φ(x|z)[logp_θ(x|z)]} + D_{KL}(q_φ(z|x)||p(z))\
L(θ,φ;x,z) = E_q[log(Decoder的输出分布)] + D_{KL}(Encoder的输出分布||预设的正太分布)\
L(θ,φ;x,z) = \frac{1}{m}\sum^m_{i=1}(x_i-\hat{x_i})^2 + D_{KL}(q_φ(z|x)||p(z))
$$
后半部分的KL 散度控制 Encoder 输出类正太分布,而前半部分的期望则是重构损失,用于衡量输入与输出的差异。在实际的代码编写中,一般使用MSE代替左半部分。