一、Overview
[Kaggle竞赛地址](ML2021Spring-hw1 | Kaggle)
竞赛内容:根据三天内的疫情相关指标来预测第三天的 tested_positive
训练数据格式:2700 * 94(40 states + day1(18) + day2(18) + day3(18)),最后一维即要预测的 tested_positive
测试数据格式:893 * 93(40 states + day1(18) + day2(18) + day3(17))

二、Medium Baseline
- 简单特征选择:40 states + 前两天的 test_positive
1 | feats = [i for i in range(40)] + [57, 75] |
三、Strong Baseline
特征选择
1
2
3
4
5# 使用 sklearn 的 feature_selection 方法,选择与目标相关的 k 个特征(这里 k 取 15)
feats_select = SelectKBest(f_regression, k=15).fit(data[:, :-1], data[:, -1])
print(feats_select.get_support(True))
[40, 41, 42, 43, 57, 58, 59, 60, 61, 75, 76, 77, 78, 79, 92]训练样本
1 | # 将训练集与验证集之比上升到15:1 |
- 网络结构
1 | # 增加dropout和BN层(dropout中的p是指变成0的概率) |
优化器
1
2# 采用Adam优化器, lr使用默认的1e-3
nn.optim.Adam(lr = 0.001)batch_size
1
2# 使用较小的batch_size,可以更新model多次
batch_size = 128正则化
1
2
3
4
5
6
7
8
9
10# 此处采用L2正则来控制weights, 不过使用之后效果并不明显
def cal_loss(self, pred, target):
''' Calculate loss '''
# TODO: you may implement L2 regularization here
regularization_loss = 0
for param in model.parameters():
# TODO: you may implement L1/L2 regularization here
# regularization_loss += torch.sum(abs(param)) # L1正则项
regularization_loss += torch.sum(param ** 2) # L2正则项
return self.criterion(pred, target) + 0.00075 * regularization_loss
Score
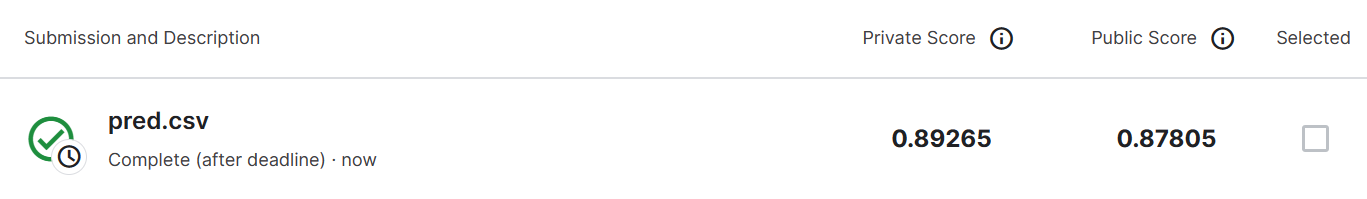
public strong baseline:0.88017
private strong baseline:0.89266