设计模式 1. 概述 编写软件的过程中,程序员面临着来自耦合性 、内聚性 、可维护性 、可拓展性 、重用性 、灵活性 等多方面的挑战,而设计模式是为了让软件具有更好的
代码重用性 :相同功能的代码,不用多次编写可读性 :编程规范性,便于其他程序员的阅读和理解可拓展性 :当需要增加新的功能时,非常的方便,不用大量修改原代码可靠性 :当增加新的功能后,对原来的功能没有任何的影响高内聚 :尽量一个方法(类)完成一个(类)事情低耦合 :减少方法(类)内部对其他方法(类)的使用,降低模块之间的依赖作用
2. 七大原则 2.1 单一职责原则 一个类只负责一个功能领域中的相应职责,或者可以定义为:就一个类而言,应该只有一个引起它变化的原因。
例如,类 A 负责两个不同职责:职责1,职责2。当职责1需求变更而改变 A 时,可能导致职责 2 出错,所以要将类 A 的粒度分解为 A1,A2。
代码如下 ,所有的交通工具都用的一个run方法,以至于潜艇能在路上跑,这肯定是不行的,因此我们要加以修改。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class SingleResponsibility public static void main (String[] args) new Vehicle("汽车" ).run(); new Vehicle("飞机" ).run(); new Vehicle("潜艇" ).run(); } } class Vehicle String name; public Vehicle (String name) this .name = name; } public void run () System.out.println(name + "在路上跑" ); } }
方案1 ,将 Vehicle 分解为三个类,这样子改动非常大,还要同时修改客户端!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 package com.yqx.designpattern.principle.improve;public class SingleResponsibility1 public static void main (String[] args) new LandVehicle("汽车" ).run(); new SeaVehicle("飞机" ).run(); new SkyVehicle("潜艇" ).run(); } } class LandVehicle String name; public LandVehicle (String name) this .name = name; } public void run () System.out.println(name + "在路上跑" ); } } class SeaVehicle String name; public SeaVehicle (String name) this .name = name; } public void run () System.out.println(name + "在海里游" ); } } class SkyVehicle String name; public SkyVehicle (String name) this .name = name; } public void run () System.out.println(name + "在天上飞" ); } }
方案2 ,将原 Vehicle 中的 run 方法拆解为三个方法,虽然没有在类上遵循单一职责的方法,但是在方法上遵守了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class SingleResponsibility2 public static void main (String[] args) new Vehicle("汽车" ).run(); new Vehicle("飞机" ).swim(); new Vehicle("潜艇" ).fly(); } } class Vehicle String name; public Vehicle (String name) this .name = name; } public void run () System.out.println(name + "在路上跑" ); } public void swim () System.out.println(name + "在海里游" ); } public void fly () System.out.println(name + "在天上飞" ); } }
降低类的复杂度,一个类只负责一项职责。
提高类的可读性,可维护性。
降低变更引起的风险。
通常情况下,我们应当遵守单一职责原则,只有当逻辑足够简单且类中的方法足够少时,才可以在代码级违反单一职责原则(见方案2)。
2.2 接口隔离原则
创建类时要使用多个专门的接口,而不使用单一的总接口,即客户端不应该依赖那些它不需要的接口。
类间的依赖关系应该建立在最小的接口上。
接口的含义 :
一个接口代表一个角色,不应该将不同的角色都交给一个接口,因为这样可能会形成一个臃肿的大接口(参考 jdk 中的 stack 类)
特定语言的接口,表示接口仅仅是提供客户端需要的行为,客户端不需要的行为则隐藏起来,应当为客户端提供尽可能小的单独的接口,而不要提供大的总接口。
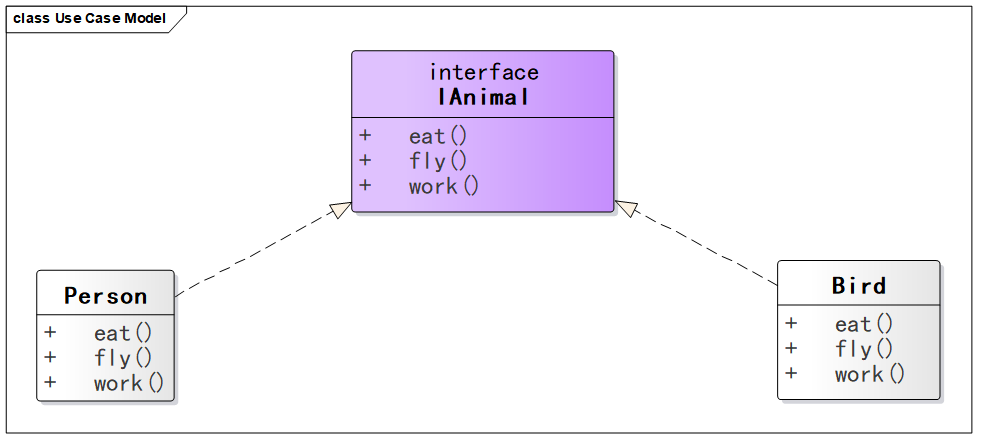
代码如下 ,动物接口中定义了三个方法,eat 、work 和 fly ,可是对于实现类 Person 而言,根本就用不到 fly() 这个方法。同理实现类 Bird 也不需要 work()。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 interface IAnimal void eat () void work () void fly () } class Person implements IAnimal private String name; public Person (String name) this .name = name; } @Override public void eat () System.out.println(name + "在吃饭" ); } @Override public void work () System.out.println(name + "在工作" ); } @Override public void fly () System.out.println(name + "不会飞" ); } } class Bird implements IAnimal private String name; public Bird (String name) this .name = name; } @Override public void eat () System.out.println(name + "在吃饭" ); } @Override public void work () System.out.println(name + "不工作" ); } @Override public void fly () System.out.println(name + "在翱翔" ); } }
这是对应的 UML 图。
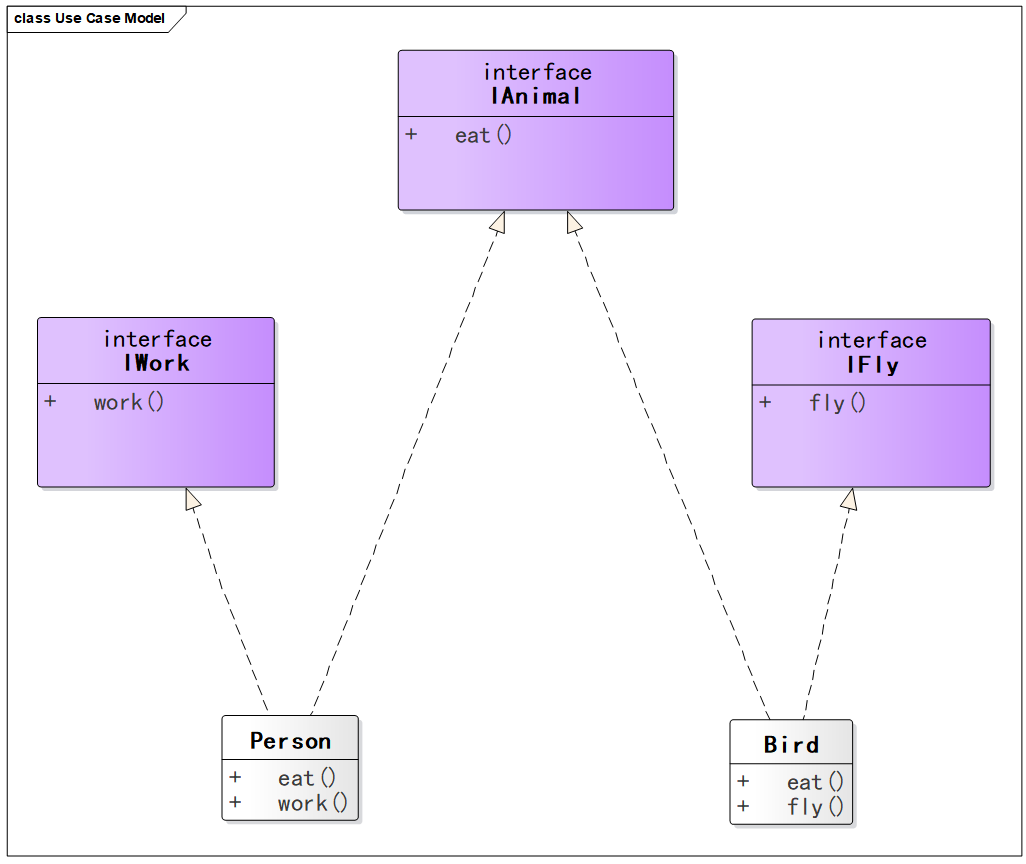
修改如下 ,将作为动物都拥有的 eat 方法保留下来,而 fly 和 work 则单独拎出来作为两个接口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 interface IAnimal void eat () } interface IWork void work () } interface IFly void fly () } class Person implements IAnimal , IWork private String name; public Person (String name) this .name = name; } @Override public void eat () System.out.println(name + "在吃饭" ); } @Override public void work () System.out.println(name + "在工作" ); } } class Bird implements IAnimal , IFly private String name; public Bird (String name) this .name = name; } @Override public void eat () System.out.println(name + "在吃饭" ); } @Override public void fly () System.out.println(name + "在翱翔" ); } }
UML 图如下。
2.3 依赖倒转原则
高层模块不应该依赖底层模块,二者都应该依赖其抽象。
抽象不应该依赖细节,而细节应该依赖抽象。
依赖倒转的中心思想是面向接口编程 。
相较于细节的多变性,抽象的东西要稳定得多,以抽象为基础搭建的架构要比以细节为基础所搭建的架构要稳定得多。
使用接口或抽象类的目的是制定好规范,而不涉及任何具体的操作,把展现细节的任务交给他们的实现类 去完成。
代码如下 ,Person 类中有 receiveEmail() 来专门接受邮件消息,可万一后面程序拓展,需要接受短信、qq、微信等消息呢?那就只能添加数个方法对应数个接受信息格式,麻烦之至!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class ReverseDependency public static void main (String[] args) new Person().receiveEmail(new Email("每日一报未填报!" )); } } class Email private String msg; public String getMsg () return msg; } public Email (String msg) this .msg = msg; } } class Person public void receiveEmail (Email email) System.out.println("收到一封邮件:" + email.getMsg()); } }
修改如下 ,方法中只需传入类的抽象类型(接口)即可,让所有的实体类去实现这个抽象类型(接口),记住:依赖于接口 !!!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 public class ReverseDependency public static void main (String[] args) Person1 person1 = new Person1(); Person2 person2 = new Person2(); Person3 person3 = new Person3(new Wechat("每日一报未填报!" )); person1.receiveEmail(new Email("每日一报未填报!" )); person2.setReceiver(new QQ("每日一报未填报!" )); person2.receiveEmail(); person3.receiveEmail(); } } interface IReceiver String getMsg () ; String getName () ; } class Email implements IReceiver private String msg; public String getMsg () return msg; } @Override public String getName () return "Email" ; } public Email (String msg) this .msg = msg; } } class QQ implements IReceiver private String msg; public String getMsg () return msg; } @Override public String getName () return "QQ" ; } public QQ (String msg) this .msg = msg; } } class Wechat implements IReceiver private String msg; public String getMsg () return msg; } @Override public String getName () return "Wechat" ; } public Wechat (String msg) this .msg = msg; } } class Person1 public void receiveEmail (IReceiver receiver) System.out.println(receiver.getName() + "收到一条消息:" + receiver.getMsg()); } } class Person2 private IReceiver receiver; public void setReceiver (IReceiver receiver) this .receiver = receiver; } public void receiveEmail () System.out.println(receiver.getName() + "收到一条消息:" + receiver.getMsg()); } } class Person3 private IReceiver receiver; public Person3 (IReceiver receiver) this .receiver = receiver; } public void receiveEmail () System.out.println(receiver.getName() + "收到一条消息:" + receiver.getMsg()); } }
2.4 里氏替换原则
Barbara Liskov 提出:
标准定义:如果对每一个类型为 S 的对象 o1,都有类型为 T 的对象 o2,使得以 T 定义的所有程序 P 在所有的对象 o1 代换 o2 时,程序 P 的行为没有变化,那么类型 S 是类型 T 的子类型。
说人话就是,所有引用基类(父类的)地方都可以用子类来替换,且程序不会有任何的异常 ,但反过来通常来说就是错误的!!!毕竟可以说人是动物,但不能说动物是人。
里氏替换原则是实现开闭原则的重要方式之一,由于使用基类的所有地方都可以用子类来替换,因此在程序中尽量使用基类来定义对象,在运行时确定其子类类型。
2.4.1 里氏替换原则约束
子类必须实现父类的抽象方法,但尽量不要重写(覆盖)父类的非抽象(已实现)方法,会让逻辑关系变得混乱。
子类中可以添加特有方法,此时则无法在以父类定义的对象中使用该方法,除非在使用的时候强转成子类进行调用。
当子类覆盖或实现父类的方法时,方法的前置条件(形参)要比父类的形参更宽松。
当子类覆盖或实现父类的方法时,方法的后置条件(返回值)要比父类的返回值更宽松。
为什么子类的前置条件要比父类更宽松?
下述代码中,Father 类中的 doSomething() 是 HashMap 类型的,而其子类 Son 则是 HashMap 的实现接口 Map 类型,显然,更宽松了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class test public static void main (String[] args) Father father = new Father(); Son son = new Son(); HashMap map = new HashMap(); father.doSomething(map); son.doSomething(map); } } class Father public Collection doSomething (HashMap map) System.out.println("父类被执行" ); return map.values(); } } class Son extends Father public Collection doSomething (Map map) System.out.println("子类被执行" ); return map.values(); } }
执行结果正如里氏替换原则说的那样:所有引用基类(父类的)地方都可以用子类来替换,且程序不会有任何的异常 ,子类代替父类,子类的方法不被执行
1 2 3 4 父类被执行 父类被执行 Process finished with exit code 0
继承包含这样一层含义:父类中凡是已经实现好的方法(相对于抽象方法而言),实际上是在设定一系列的规范和契约,虽然它不强制要求所有的子类必须遵从这些契约,但是如果子类对这些非抽象方法任意修改,就会对整个继承体系造成破坏。而里氏替换原则就是表达了这一层含义。
设置子类的方法比父类的形参条件更宽松,在没有重写的情况下,父类对象调用方法是就会优先调用父类中的方法,而不是子类中重载的方法。
下面我们反过来 ,假如子类前置条件更严格呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class test public static void main (String[] args) Father father = new Father(); Son son = new Son(); HashMap map = new HashMap(); father.doSomething(map); son.doSomething(map); } } class Father public Collection doSomething (Map map) System.out.println("父类被执行" ); return map.values(); } } class Son extends Father public Collection doSomething (HashMap map) System.out.println("子类被执行" ); return map.values(); } }
毫无疑问地,会执行子类的方法。
1 2 3 4 父类被执行 父类被执行 Process finished with exit code 0
调用了子类,子类在没有覆写父类的方法的前提下,子类方法被执行了,这会引起业务逻辑混乱,因为在实际应用中父类一般是抽象类,子类是实现类,你传递一个这样的实现类就会歪曲了父类的意图,引起业务逻辑混乱,所以子类中方法的前置条件必须与超类中被覆写的方法的前置条件相同或更宽松。
为什么子类的后置条件要比父类更严格?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class test public static void main (String[] args) Father father = new Father(); Son son = new Son(); HashMap map = new HashMap(); father.doSomething(map); son.doSomething(map); } } class Father public ArrayList doSomething (Map map) System.out.println("父类被执行" ); return new ArrayList(map.values()); } } class Son extends Father public List doSomething (Map map) System.out.println("子类被执行" ); return new ArrayList(map.values()); } }
运行结果直接报兼容异常的错误,不过想想也能知道
如果子类方法返回值类型比父类更严格,那么子类的返回值是可以隐式转换为父类的。
而如果子类方法返回值类型比父类更宽松,那么子类的返回值则无法与原代码兼容!!!需要强转等手段,但现在从编译期间就解决了这个问题,直接报错。
1 2 java: com.yqx.designpattern.Son中的doSomething(java.util.Map)无法覆盖com.yqx.designpattern.Father中的doSomething(java.util.Map) 返回类型java.util.List与java.util.ArrayList不兼容
2.4.2 代码 下述代码中,子类 B 重写了父类 A 中的 func1() 方法,而自己却不自知。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class Liskov public static void main (String[] args) A a = new A(); B b = new B(); System.out.println("11 - 3 = " + a.func1(11 , 3 )); System.out.println("1 - 8 = " + a.func1(1 , 8 )); System.out.println("==================================" ); System.out.println("11 - 3 = " + b.func1(11 , 3 )); System.out.println("1 - 8 = " + b.func1(1 , 8 )); System.out.println("11 + 3 + 9 = " + b.func2(11 , 3 )); } } class A public int func1 (int num1, int num2) return num1 - num2; } } class B extends A public int func1 (int num1, int num2) return num1 + num2; } public int func2 (int num1, int num2) return func1(num1, num2) + 9 ; } }
执行结果则出现了很离谱的情况,以为自己还调用的是父类的 func1(),导致加减颠倒。
1 2 3 4 5 6 11 - 3 = 8 1 - 8 = -7 ================================== 11 - 3 = 14 1 - 8 = 9 11 + 3 + 9 = 23
在实际编程中,我们常常会通过重写父类的方法来完成新的功能,这样写起来虽然简单,但整个继承体系的复用性会比较差,特别是运行多态比较频繁的时候。
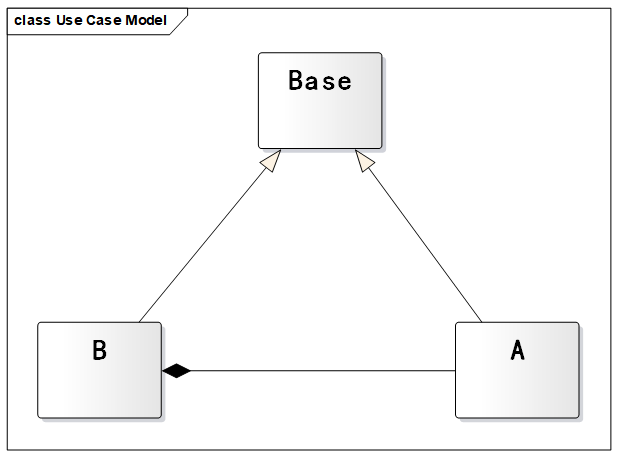
通用的方法是:让原来的父类和子类都继承一个更通俗的基类 ,将原有的继承关系取消,进而采用依赖,组合,聚合 等关系代替。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class Liskov public static void main (String[] args) A a = new A(); B b = new B(); System.out.println("11 - 3 = " + a.func1(11 , 3 )); System.out.println("1 - 8 = " + a.func1(1 , 8 )); System.out.println("==================================" ); System.out.println("11 + 3 = " + b.func1(11 , 3 )); System.out.println("1 + 8 = " + b.func1(1 , 8 )); System.out.println("1 - 8 = " + b.func3(1 , 8 )); System.out.println("11 + 3 + 9 = " + b.func2(11 , 3 )); } } class Base } class A extends Base public int func1 (int num1, int num2) return num1 - num2; } } class B extends Base A a = new A(); public int func1 (int num1, int num2) return num1 + num2; } public int func2 (int num1, int num2) return func1(num1, num2) + 9 ; } public int func3 (int num1, int num2) return a.func1(num1, num2); } }
UML 图如下。
2.5 开闭原则 开闭原则是面向对象的可复用设计的第一块基石,它是最重要的面向对象设计原则,定义如下:
一个软件实体应当对扩展开放,对修改关闭,即软件实体应尽量在不修改原有代码的情况下进行扩展。
开闭原则的优势:
可以使原有代码依旧可以运行,只需要对扩展的代码进行测试即可
可以提高代码的复用性
可以提高系统的维护性
如何使用开闭原则:
抽象约束
通过接口或者抽象类约束扩展,对扩展进行边界限定,不允许出现在接口或抽象类中不存在的 public 方法。
参数类型、引用对象尽量使用接口或者抽象类,而不是实现类。
抽象层尽量保持稳定,一旦确定就不允许修改。
元数据控制模块行为,通俗点来说就是通过配置文件来操控数据(Spring)
约定由于配置
封装变化
将相同的变化封装到一个接口或者类中
将不同的变化封装到不同的接口或者类中
代码部分
UML 图如下。
代码如下,一个简易绘制图形的类。
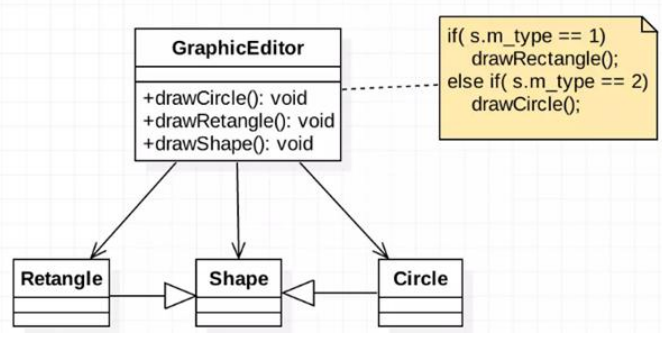
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 package com.yqx.designpattern.principle.ocp;public class Ocp public static void main (String[] args) GraphicEditor graphicEditor = new GraphicEditor(); graphicEditor.drawShape(new Rectangle()); graphicEditor.drawShape(new Circle()); graphicEditor.drawShape(new Triangle()); } } class GraphicEditor public void drawShape (Shape s) if (s.type == 1 ){ drawRectangle(); }else if (s.type == 2 ){ drawCircle(); }else { drawTriangle(); } } public void drawRectangle () System.out.println("绘制矩形" ); } public void drawCircle () System.out.println("绘制圆形" ); } public void drawTriangle () System.out.println("绘制三角形" ); } } class Shape int type; } class Rectangle extends Shape public Rectangle () super .type = 1 ; } } class Circle extends Shape public Circle () super .type = 2 ; } } class Triangle extends Shape public Triangle () super .type = 3 ; } }
当我们想要扩展性内容,比如画一个五角星时,改动非常多,还违背了 ocp 原则!!!
修改如下,有点类似于依赖倒转里面的例子,这不过这里改成了抽象类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 public class Ocp public static void main (String[] args) GraphicEditor graphicEditor = new GraphicEditor(); graphicEditor.drawShape(new Rectangle()); graphicEditor.drawShape(new Circle()); graphicEditor.drawShape(new Triangle()); } } class GraphicEditor public void drawShape (Shape s) s.draw(); } } abstract class Shape int type; public abstract void draw () } class Rectangle extends Shape public Rectangle () super .type = 1 ; } @Override public void draw () System.out.println("绘制矩形" ); } } class Circle extends Shape public Circle () super .type = 2 ; } @Override public void draw () System.out.println("绘制圆形" ); } } class Triangle extends Shape public Triangle () super .type = 3 ; } @Override public void draw () System.out.println("绘制三角形" ); } }
2.6 迪米特法则
一个对象应该对其他对象保持最少的了解。
类与类的关系越密切,耦合度越大。
迪米特法则(Demeter Principle)又叫最少知道原则,即一个类对自己依赖的类知道的越少越好 。也就是说,对于被依赖的类不管多么复杂,都尽量将逻辑封装在类的内部。对外除了提供的 public 方法,不对外泄露任何信息。
迪米特法则还有个更简单的定义,只与直接的朋友通信。
直接的朋友 :每个对象都会和其他对象有耦合关系 ,只要两个对象之间有耦合关系,那我们就说这两个对象之间是朋友关系。耦合的方式有很多中:依赖、关联、组合、聚合等。其中,我们称出现在成员变量、方法参数、方法返回值 中的类为直接的朋友,而出现在局部变量中的类为间接的朋友,也就是说,陌生的类最好不要以局部变量的形式出现在类的内部 。
代码如下 ,只能说是稀碎的耦合度了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 public class Demeter public static void main (String[] args) new SchoolManager().printAllEmployee(new CollegeManager()); } } class Employee private int id; public int getId () return id; } public void setId (int id) this .id = id; } } class CollegeEmployee private int id; public int getId () return id; } public void setId (int id) this .id = id; } } class CollegeManager public List<CollegeEmployee> getAllEmployees () List<CollegeEmployee> list = new ArrayList<>(); for (int i = 0 ; i < 10 ; i++) { CollegeEmployee manager = new CollegeEmployee(); manager.setId(i + 1 ); list.add(manager); } return list; } } class SchoolManager public List<Employee> getAllEmployees () List<Employee> list = new ArrayList<>(); for (int i = 0 ; i < 5 ; i++) { Employee manager = new Employee(); manager.setId(i + 1 ); list.add(manager); } return list; } public void printAllEmployee (CollegeManager manager) List<CollegeEmployee> list1 = manager.getAllEmployees(); System.out.println("----------学院员工---------" ); for (CollegeEmployee employee : list1) { System.out.print(employee.getId() + " " ); } System.out.println(); List<Employee> list2 = getAllEmployees(); System.out.println("---------学校总部员工----------" ); for (Employee employee : list2) { System.out.print(employee.getId() + " " ); } } }
SchoolManager 违反了迪米特法则,局部变量中还包含了一个陌生的类!!!要避免类中出现这样非直接朋友关系的耦合。
修改如下 ,将打印学院员工的实现放在 CollegeManager 类中,而在 SchoolEmployee 类中直接调用 CollegeManager 的打印方法即可!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 public class Demeter public static void main (String[] args) new SchoolManager().printSchoolEmployee(new CollegeManager()); } } class Employee private int id; public int getId () return id; } public void setId (int id) this .id = id; } } class CollegeEmployee private int id; public int getId () return id; } public void setId (int id) this .id = id; } } class CollegeManager public List<CollegeEmployee> getAllEmployees () List<CollegeEmployee> list = new ArrayList<>(); for (int i = 0 ; i < 10 ; i++) { CollegeEmployee manager = new CollegeEmployee(); manager.setId(i + 1 ); list.add(manager); } return list; } public void printCollegeManager () List<CollegeEmployee> list1 = getAllEmployees(); System.out.println("----------学院员工---------" ); for (CollegeEmployee employee : list1) { System.out.print(employee.getId() + " " ); } } } class SchoolManager public List<Employee> getAllEmployees () List<Employee> list = new ArrayList<>(); for (int i = 0 ; i < 5 ; i++) { Employee manager = new Employee(); manager.setId(i + 1 ); list.add(manager); } return list; } public void printSchoolEmployee (CollegeManager manager) manager.printCollegeManager();; System.out.println(); List<Employee> list2 = getAllEmployees(); System.out.println("---------学校总部员工----------" ); for (Employee employee : list2) { System.out.print(employee.getId() + " " ); } } }
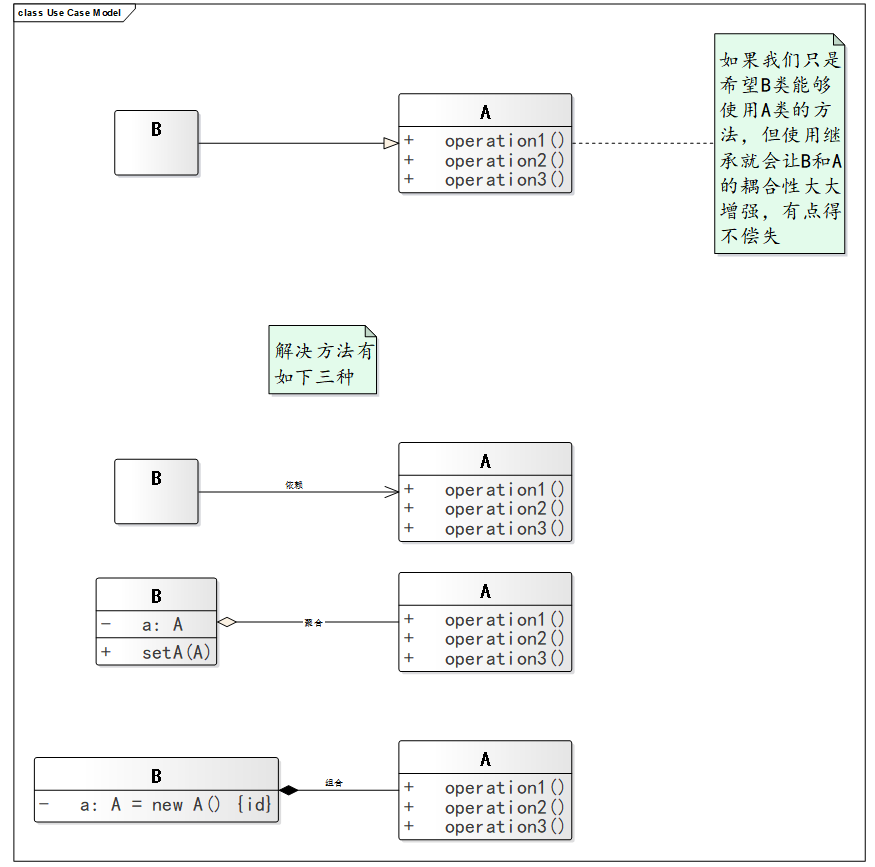
2.7 合成复用原则 原则是尽量使用合成/聚合的方式,而不是使用继承已达到复用的效果。
通过合成复用原则来使一些已有的对象使之成为对象的一部分,一般通过组合/聚合关系来实现,而尽量不要使用继承。因为组合和聚合可以降低类之间的耦合度,而继承会让系统更加复杂,最重要的一点会破坏系统的封装性,因为继承会把基类的实现细节暴露给子类,同时如果基类变化,子类也必须跟着改变,而且耦合度会很高。
3. UML 类图 类图是面向对象系统建模中最常用和最重要的图,是定义其它图的基础。类图主要是用来显示系统中的类、接口以及它们之间的静态结构和关系的一种静态模型。类图中最基本的元素是类、接口。软件设计师设计出类图后,程序员就可以用代码实现类图中包含的内容。
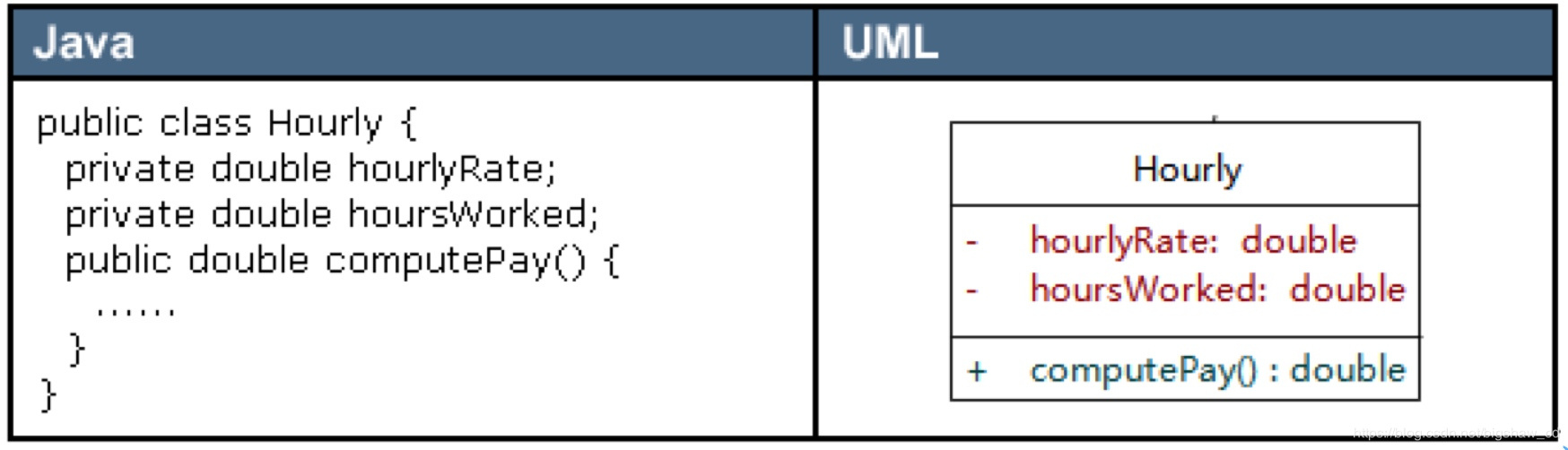
3.1 类,接口,包 3.1.1 具体类 具体类在类图中用矩形框表示,矩形框分为三层:第一层是类名字;第二层是成员变量;第三层是类的方法。成员变量以及方法前的访问修饰符用符号来表示:
“**+**” 表示 public
“**-**” 表示 private
“**#**” 表示 protected
没有符号表示 default
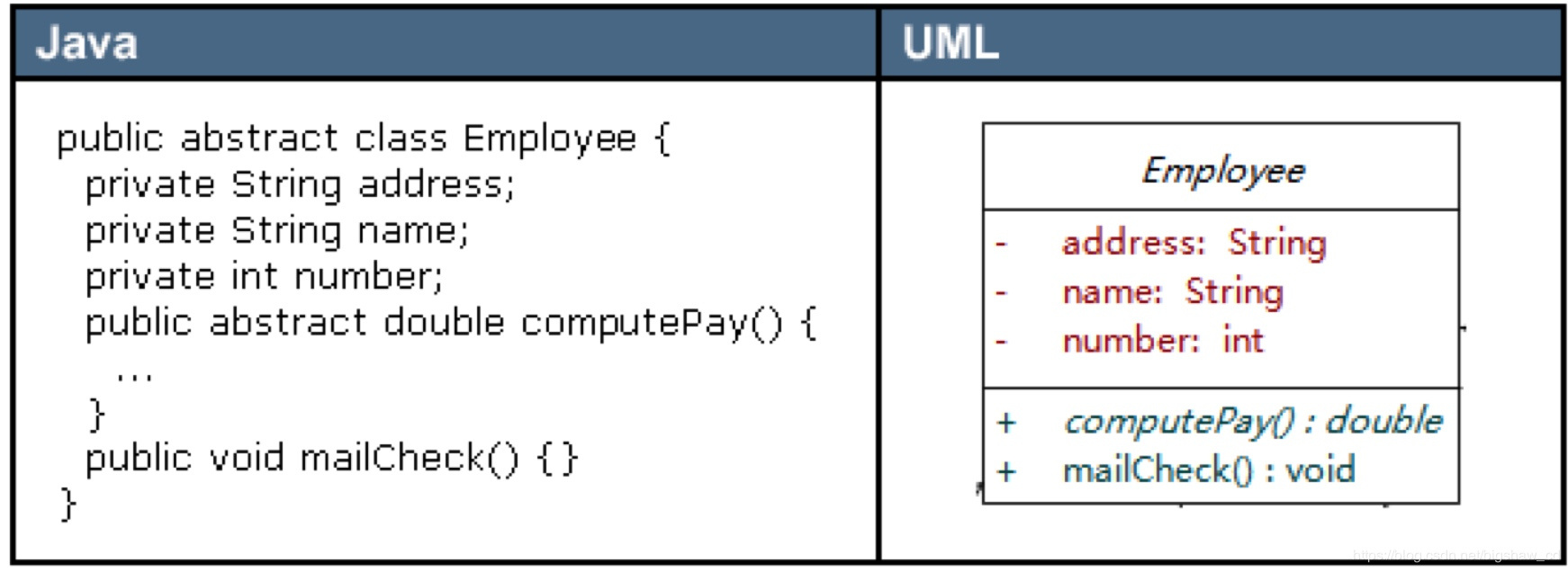
3.1.2 抽象类 抽象类在UML类图中同样用矩形框表示,但是抽象类的类名以及抽象方法的名字都用斜体字表示:
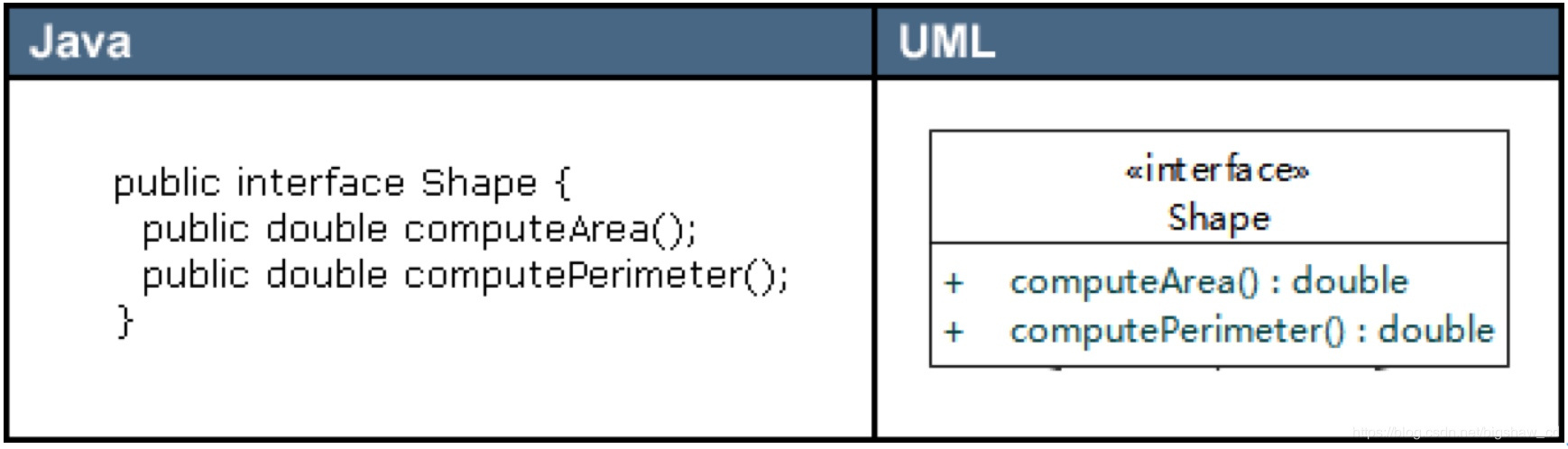
3.1.3 接口 接口在类图中也是用矩形框表示,但是与类的表示法不同的是,接口在类图中的第一层顶端用构造型 <<interface>>表示,下面是接口的名字,第二层是方法,如下图所示。
3.1.4 包 类和接口一般都出现在包中,UML类图中包的表示形式如下图所示。
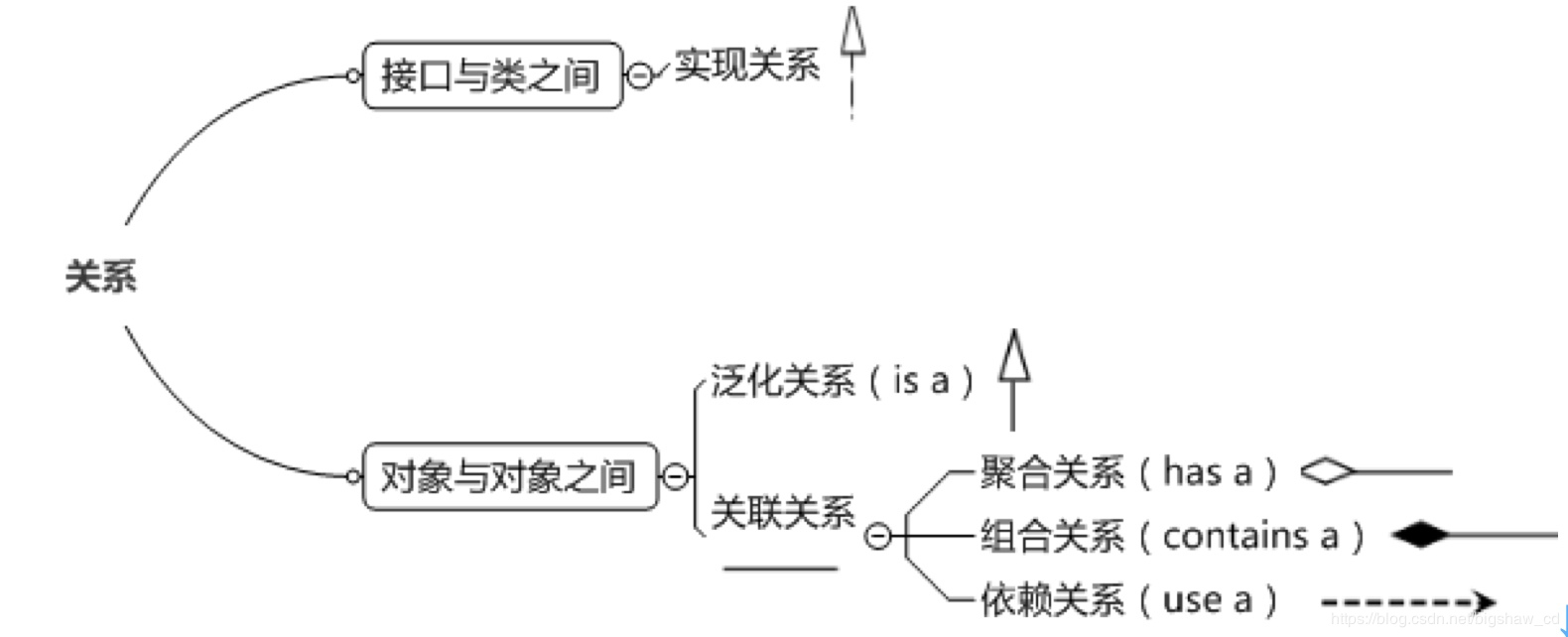
3.2 类图中的关系 类和类、类和接口、接口和接口之间存在一定关系,UML类图中一般会有连线指明它们之间的关系。关系共有六种类型,分别是实现关系、泛化关系、关联关系、依赖关系、聚合关系、组合关系。
3.2.1 实现关系 实现关系是指接口及其实现类之间的关系。在UML类图中,实现关系用空心三角和虚线组成的箭头来表示,从实现类指向接口,如图所示。在Java代码中,实现关系可以直接翻译为关键字 implements。
3.2.2 泛化关系 泛化关系(Generalization)是指对象与对象之间的继承关系。如果对象A和对象B之间的“is a”关系成立,那么二者之间就存在继承关系,对象B是父对象,对象A是子对象。例如,一个年薪制员工“is a”员工,很显然年薪制员工Salary对象和员工Employee对象之间存在继承关系,Employee对象是父对象,Salary对象是子对象。
在UML类图中,泛化关系用空心三角和实线组成的箭头表示,从子类指向父类,如图8所示。在Java代码中,对象之间的泛化关系可以直接翻译为关键字 extends。
3.2.3 关联关系 关联关系(Association)是指对象和对象之间的连接,它使一个对象知道另一个对象的属性和方法。在Java中,关联关系的代码表现形式为一个对象含有另一个对象的引用。也就是说,如果一个对象的类代码中,包含有另一个对象的引用,那么这两个对象之间就是关联关系。
关联关系有单向关联和双向关联。如果两个对象都知道(即可以调用)对方的公共属性和操作,那么二者就是双向关联。如果只有一个对象知道(即可以调用)另一个对象的公共属性和操作,那么就是单向关联。大多数关联都是单向关联,单向关联关系更容易建立和维护,有助于寻找可重用的类。
在UML图中,双向关联关系用带双箭头的实线或者无箭头的实线双线表示。单向关联用一个带箭头的实线表示,箭头指向被关联的对象,如图9所示。这就是导航性(Navigatity)。
一个对象可以持有其它对象的数组或者集合。在UML中,通过放置多重性(multipicity)表达式在关联线的末端来表示。多重性表达式可以是一个数字、一段范围或者是它们的组合。多重性允许的表达式示例如下:
数字:精确的数量
*或者0..*:表示0到多个0..1:表示0或者1个,在Java中经常用一个空引用来实现1..*:表示1到多个
关联关系又分为依赖关联、聚合关联和组合关联三种类型。
3.2.4 依赖关系 依赖(Dependency)关系是一种弱关联关系。如果对象A用到对象B,但是和B的关系不是太明显的时候,就可以把这种关系看作是依赖关系。如果对象A依赖于对象B,则 A “use a” B。比如驾驶员和汽车的关系,驾驶员使用汽车,二者之间就是依赖关系。
在 UML 类图中,依赖关系用一个带虚线的箭头表示,由使用方指向被使用方,表示使用方对象持有被使用方对象的引用,如图所示。
依赖关系在Java中的具体代码表现形式为B为A的构造器 或方法中的局部变量 、方法或构造器的参数 、方法的返回值 ,或者A调用B的静态方法 。
下面我们用代码清单1和代码清单2所示的Java代码来演示对象和对象之间的依赖关系。
代码清单1所示的B类定义了一个成员变量 field1,一个普通方法 method1() 和一个静态方法 method2()。
1 2 3 4 5 6 7 8 9 10 11 12 public class B public String field1; public void method1 () System.println("在类B的方法1中" ); } public static void method2 () System.out.println("在类B的静态方法2中" ); } }
代码清单2所示的A类依赖于B类,在A类中定义了四个方法,分别演示四种依赖形式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class A public void method1 () B b = new B(); b.method1(); } public void method2 () B.method2(); } public void method3 (B b) String s = b.field1; } public B method4 () return new B(); } }
3.2.5 聚合关系 聚合(Aggregation)是关联关系的一种特例,它体现的是整体与部分的拥有关系,即 “has a” 的关系。此时整体与部分之间是可分离的,它们可以具有各自的生命周期,部分可以属于多个整体对象,也可以为多个整体对象共享,所以聚合关系也常称为共享关系。例如,公司部门与员工的关系,一个员工可以属于多个部门,一个部门撤消了,员工可以转到其它部门。
在UML图中,聚合关系用空心菱形加实线箭头表示,空心菱形在整体一方,箭头指向部分一方,如图11所示。
3.2.6 组合关系 组合(Composition)也是关联关系的一种特例,它同样体现整体与部分间的包含关系,即 “contains a” 的关系。但此时整体与部分是不可分的,部分也不能给其它整体共享,作为整体的对象负责部分的对象的生命周期。这种关系比聚合更强,也称为强聚合。如果A组合B,则A需要知道B的生存周期,即可能A负责生成或者释放B,或者A通过某种途径知道B的生成和释放。
例如,人包含头、躯干、四肢,它们的生命周期一致。当人出生时,头、躯干、四肢同时诞生。当人死亡时,作为人体组成部分的头、躯干、四肢同时死亡。
在UML图中,组合关系用实心菱形加实线箭头表示,实心菱形在整体一方,箭头指向部分一方。
在Java代码形式上,聚合和组合关系中的部分对象是整体对象的一个成员变量。但是,在实际应用开发时,两个对象之间的关系到底是聚合还是组合,有时候很难区别。在Java中,仅从类代码本身是区分不了聚合和组合的。如果一定要区分,那么如果在删除整体对象的时候,必须删掉部分对象,那么就是组合关系,否则可能就是聚合关系。从业务角度上来看,如果作为整体的对象必须要部分对象的参与,才能完成自己的职责,那么二者之间就是组合关系,否则就是聚合关系。
例如,汽车与轮胎,汽车作为整体,轮胎作为部分。如果用在二手车销售业务环境下,二者之间就是聚合关系。因为轮胎作为汽车的一个组成部分,它和汽车可以分别生产以后装配起来使用,但汽车可以换新轮胎,轮胎也可以卸下来给其它汽车使用。如果用在驾驶系统业务环境上,汽车如果没有轮胎,就无法完成行驶任务,二者之间就是一个组合关系。再比如网上书店业务中的订单和订单项之间的关系,如果订单没有订单项,也就无法完成订单的业务,所以二者之间是组合关系。而购物车和商品之间的关系,因为商品的生命周期并不被购物车控制,商品可以被多个购物车共享,因此,二者之间是聚合关系。
4. 设计模式详解 设计模式是程序员在面对同类软件工程设计问题所总结出来的有用的经验,模式不是代码 ,而是某类问题的通用解决方法 ,类似于算法。设计模式代表了最佳的实践,这是众多软件开发人员在经过相当长的一段时间的试验和错误总结出来的。
设计模式的本意是提高 软件的维护性,通用性和扩展性,并降低软件的复杂度。
设计模式并不局限于某种语言,java,php,c++ 都有设计模式。
4.1 设计模式类型 设计模式分为三种类型,共23个。
创建型模式: 单例模式、抽象工厂模式、原型模式、建造者模式、工厂模式。结构型模式 :适配器模式、桥接模式、装饰模式、组合模式、外观模式、享元模式、代理模式。行为型模式 :模板方法模式、命令模式、访问者模式、迭代器模式、观察者模式、中介者模式、备忘录模式、解释器模式、状态模式、策略模式、职责链模式。
4.2 单例模式 单例模式,就是采取一定的方法保证在整个软件系统中,对某个类只能存在一个对象实例 ,频繁创建销毁会消耗大量资源!并且该类只提供一个取得其对象实例的方法(静态方法)。
而单例模式的实现方法足足有8种之多,下面就一一讲解。
4.2.1 饿汉式(静态常量) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class Singleton1 public static void main (String[] args) Test1 test1 = Test1.getInstance(); Test1 test2 = Test1.getInstance(); System.out.println(test1.hashCode()); System.out.println(test2.hashCode()); System.out.println(test1 == test2); } } class Test1 private static Test1 test = new Test1(); private Test1 () } public static Test1 getInstance () return test; } }
优点:
这种写法比较简单
在类装载的时候便完成了实例化,避免了线程同步的问题。
线程安全
缺点:
也正是因为在类装载的时候就完成实例化,因此无法实现懒加载的效果。
如果自始至终都没有使用过这个实例,那么就会造成内存的浪费。
结论:这种单例模式可以使用,但可能会造成内存浪费。
4.2.2 饿汉式(静态代码块) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Test2 private static Test2 test; private Test2 () } static { test = new Test2(); } public static Test2 getInstance () return test; } }
同上不解释,仅仅是将类的实例化放在了静态代码块中。
4.2.3 懒汉式(线程不安全) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Test3 private static Test3 test; private Test3 () } public static Test3 getInstance () if (test == null ) { test = new Test3(); } return test; } }
优点:
缺点:
结论:在实际开发中,不能使用这种方式!
4.2.4 懒汉式(同步方法) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Test4 private static Test4 test; private Test4 () } public static synchronized Test4 getInstance () if (test == null ) { test = new Test4(); } return test; } }
优点:
对比上述实现,只是在方法前添加了 synchronized 修饰,便可以解决线程不安全的问题。
缺点:
结论:在实际开发中,不推荐 使用这种方式。
4.25 懒汉式(同步代码块) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Test5 private static Test5 test; private Test5 () } public static Test5 getInstance () if (test == null ) { synchronized (Test5.class){ test = new Test5(); } } return test; } }
这个 synchronized 完全没有用!
因此优缺点和 4.2.3 懒汉式 一样,甚至因为加了同步锁,性能还更差了!
结论:瞎搞!
4.2.6 懒汉式(双重检查) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Test6 private static volatile Test6 test; private Test6 () } public static Test6 getInstance () if (test == null ) { synchronized (Test6.class){ if (test == null ){ test = new Test6(); } } } return test; } }
Double-Check 概念是多线程开发中常使用到的,如上述代码中,我们进行了两个 if(test == null) 的检查,这样就能保证线程安全了。
这样,实例化代码也只执行了一次,后续访问时,判断 test != null ,便会直接 return 实例化对象,也避免了反复进行方法同步。
volatile 貌似是为了解决指令重拍的问题,等后续我学了 JUC 再回来研究研究。
优点:
结论:在实际开发中,推荐使用这种单例模式实现方式!
4.2.7 静态内部类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Test7 private Test7 () } public static Test7 getInstance () return StaticInnerClass.test; } static class StaticInnerClass private static Test7 test = new Test7(); } }
这种方式采用了类装载的机制来保证初始化实例时只有一个线程。
静态内部类方式 StaticInnerClass 在 Test7 被装载时并不会立刻实例化,而是在需要实例化时,调用 getInstance 方法,这时才开始装载 StaticInnerClass 类,从而完成 Test7 的实例化。
优点:
避免了线程不安全。
利用静态内部类的特点实现延迟加载,效率高。
结论:推荐使用!
4.2.8 枚举 优点:
结论:推荐使用!
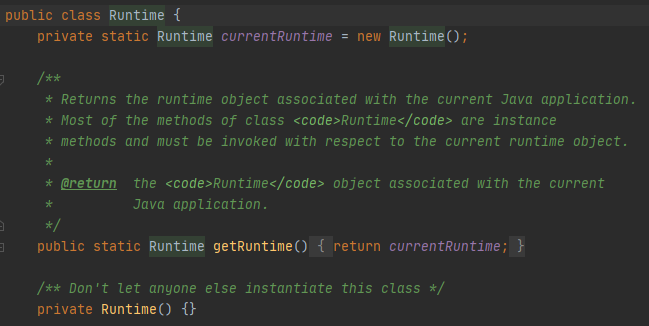
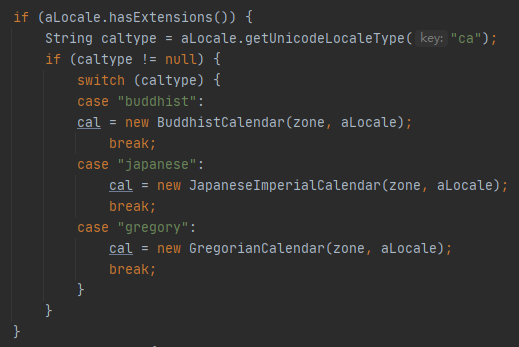
4.2.9 单例模式在 JDK 中的应用 在 JDK 中,Runtime 就是典型的单例模式,还是饿汉式的!毕竟程序运行肯定会有报运行时异常的时候。
4.2.10 小结
单例模式保证了系统内存中该类只存在一个对象,节省了系统资源,对于一些需要频繁创建销毁的对象,使用单例模式可以提高系统性能。
想要实例化单例类的时候,要使用获取对象的方法,而不是 new !
创建单例类的时候,必须要将构造方法私有化!!!
单例模式使用场景:需要频繁进行创建销毁的对象、创建对象时耗时过多或耗费资源过多,但又经常用到的对象(工具类对象)以及频繁访问数据库或文件的对象(数据源、session 工厂)。
4.3 工厂模式 4.3.1 开一家披萨店! 先来看一个披萨的项目
1) 披萨的种类有很多(比如 GreekPizza、CheesePizza 等)
2) 披萨的制作流程有 prepare,bake,cut,box
3) 完成披萨店订购功能
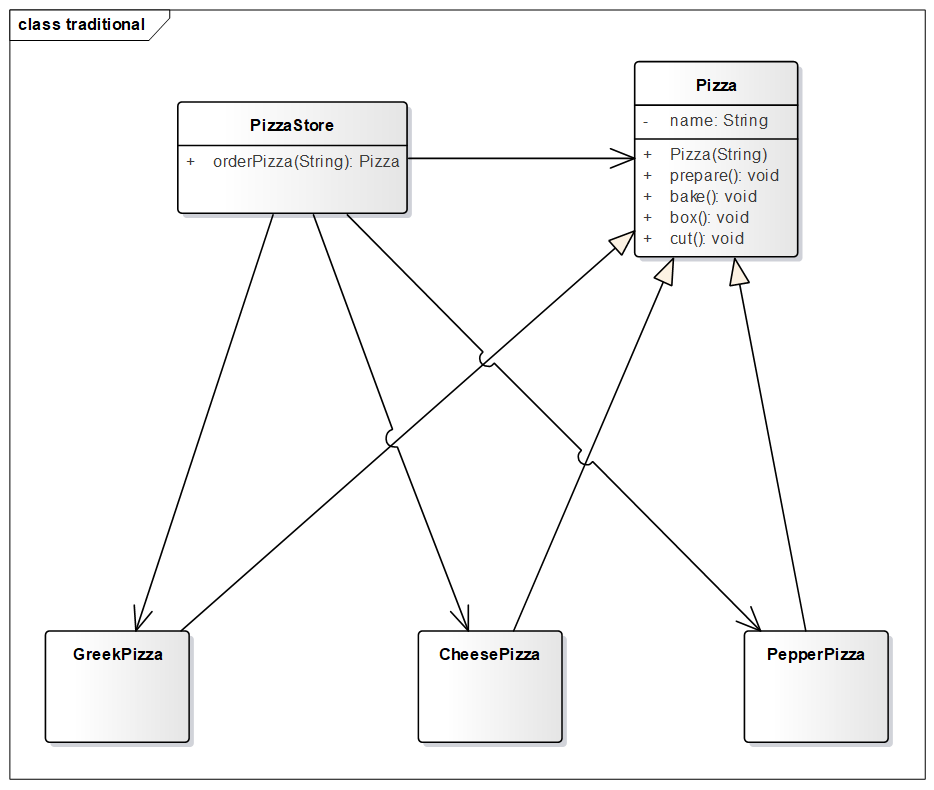
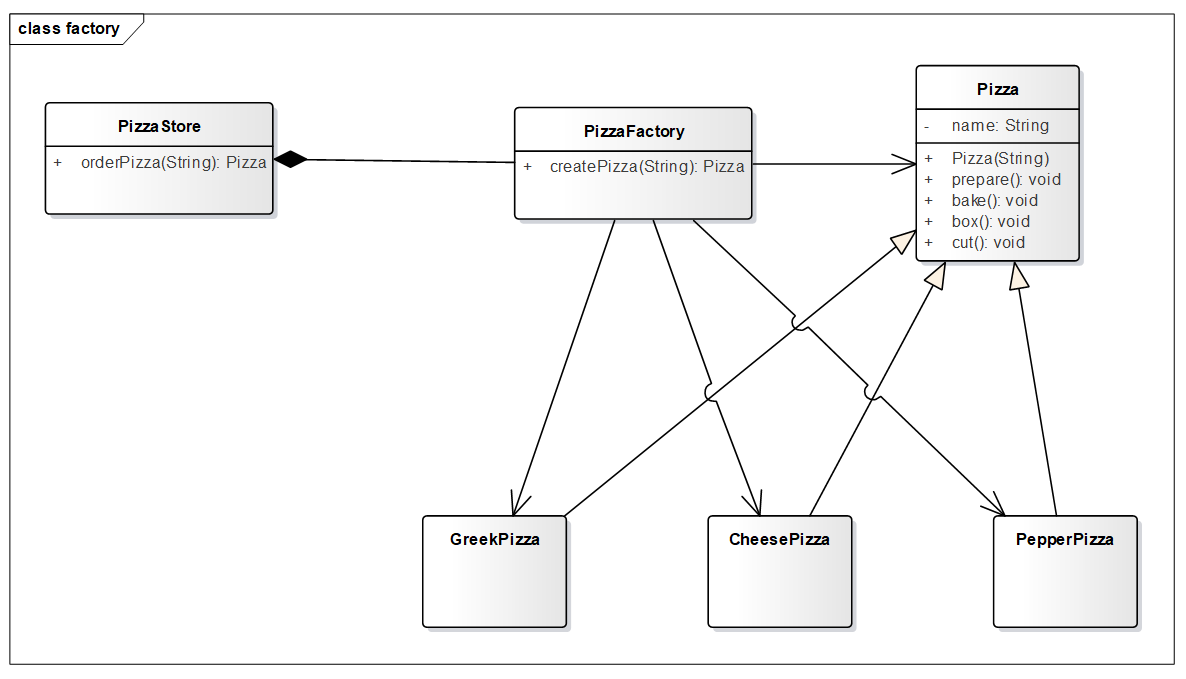
传统代码如下 ,披萨基类以及它的实现类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public abstract class Pizza private String name; public Pizza (String name) this .name = name; } void prepare () System.out.println("准备" + name + "披萨的原材料..." ); } void bake () System.out.println("烘烤" + name + "披萨..." ); } void cut () System.out.println("切割" + name + "披萨..." ); } void box () System.out.println("打包" + name + "披萨..." ); } } class GreekPizza extends Pizza public GreekPizza () super ("希腊" ); } } class CheesePizza extends Pizza public CheesePizza () super ("奶酪" ); } } class PepperPizza extends Pizza public PepperPizza () super ("胡椒" ); } }
披萨店类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public class PizzaStore public Pizza orderPizza (String name) Pizza pizza = null ; switch (name){ case "希腊" : pizza = new GreekPizza(); break ; case "奶酪" : pizza = new CheesePizza(); break ; case "胡椒" : pizza = new PepperPizza(); break ; } if (pizza == null ){ return null ; } pizza.prepare(); pizza.bake(); pizza.cut(); pizza.box(); return pizza; } public static void main (String[] args) Scanner sc = new Scanner(System.in); PizzaStore pizzaStore = new PizzaStore(); while (true ){ String name = sc.nextLine(); Pizza pizza = pizzaStore.orderPizza(name); if (pizza == null ){ System.out.println("很抱歉,本店没有" + name +"披萨" ); break ; } } } }
以上代码虽然也可以正常工作,可是假如哪儿天老板觉得希腊披萨卖得不好,或者要添加新口味如蛤蜊披萨,那就需要修改 orderPizza() 中的代码,违反了开闭原则(对修改关闭,对扩展开启)。
UML 如下,耦合严重。
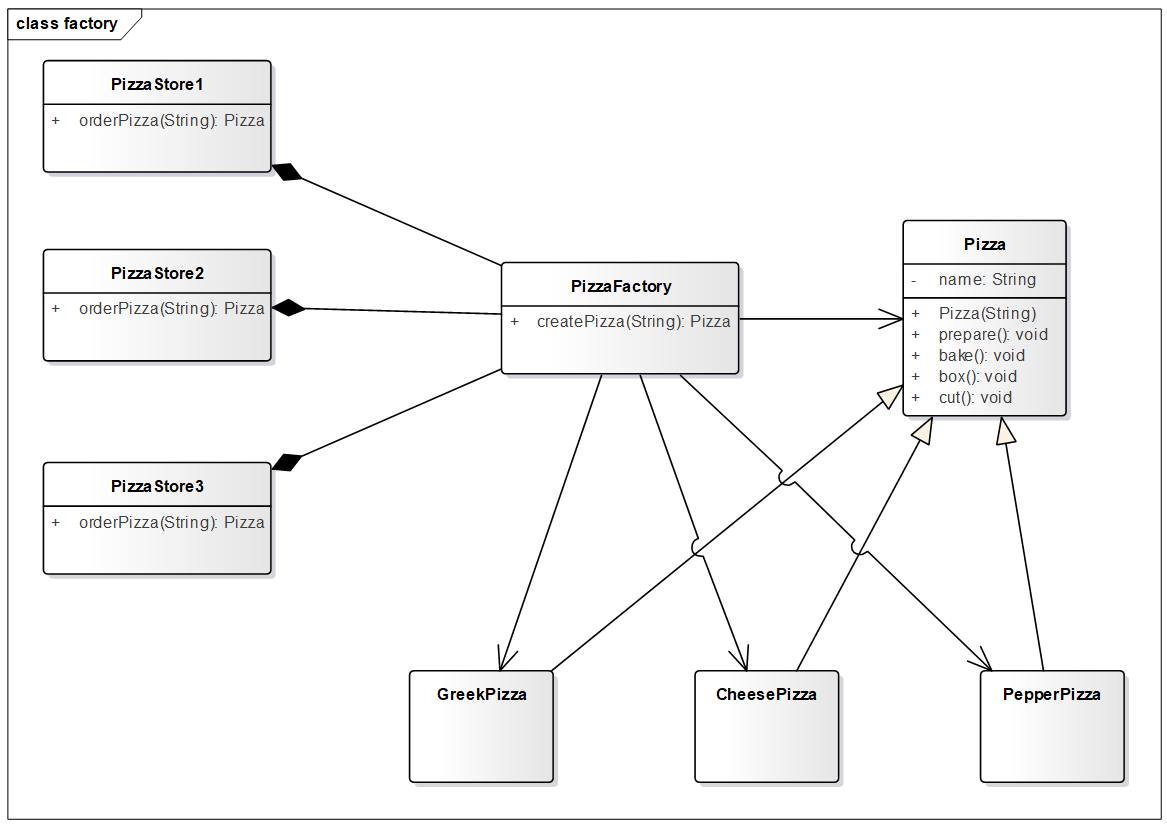
4.3.2 简单工厂实现 没有什么是加一层不能解决的,如果有就加两层!将制作披萨单独交给披萨工厂即可,以下是简单工厂的 UML 图。
代码实现
Pizza 基类和实现类没有更改,新增了 PizzaFactory 类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class PizzaFactory public Pizza createPizza (String name) Pizza pizza = null ; switch (name){ case "希腊" : pizza = new GreekPizza(); break ; case "奶酪" : pizza = new CheesePizza(); break ; case "胡椒" : pizza = new PepperPizza(); break ; } return pizza; } }
PizzaStore 类,组合了 PizzaFactory ,当然也可以使用聚合,后续决定使用什么工厂,亦或是使用单例工厂模式(结合上一讲)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class PizzaStore PizzaFactory pizzaFactory = new PizzaFactory(); public Pizza orderPizza (String name) Pizza pizza = pizzaFactory.createPizza(name); if (pizza == null ){ return null ; } pizza.prepare(); pizza.bake(); pizza.cut(); pizza.box(); return pizza; } public static void main (String[] args) Scanner sc = new Scanner(System.in); PizzaStore pizzaStore = new PizzaStore(); while (true ){ String name = sc.nextLine(); Pizza pizza = pizzaStore.orderPizza(name); if (pizza == null ){ System.out.println("很抱歉,本店没有" + name +"披萨" ); break ; } } } }
这样咋一看感觉和原先差不了多少,可是目前只有一家披萨店,当有数十家披萨店时,它们也都只需要组合 PizzaFactory 即可,而不是每家各自创建披萨!!!
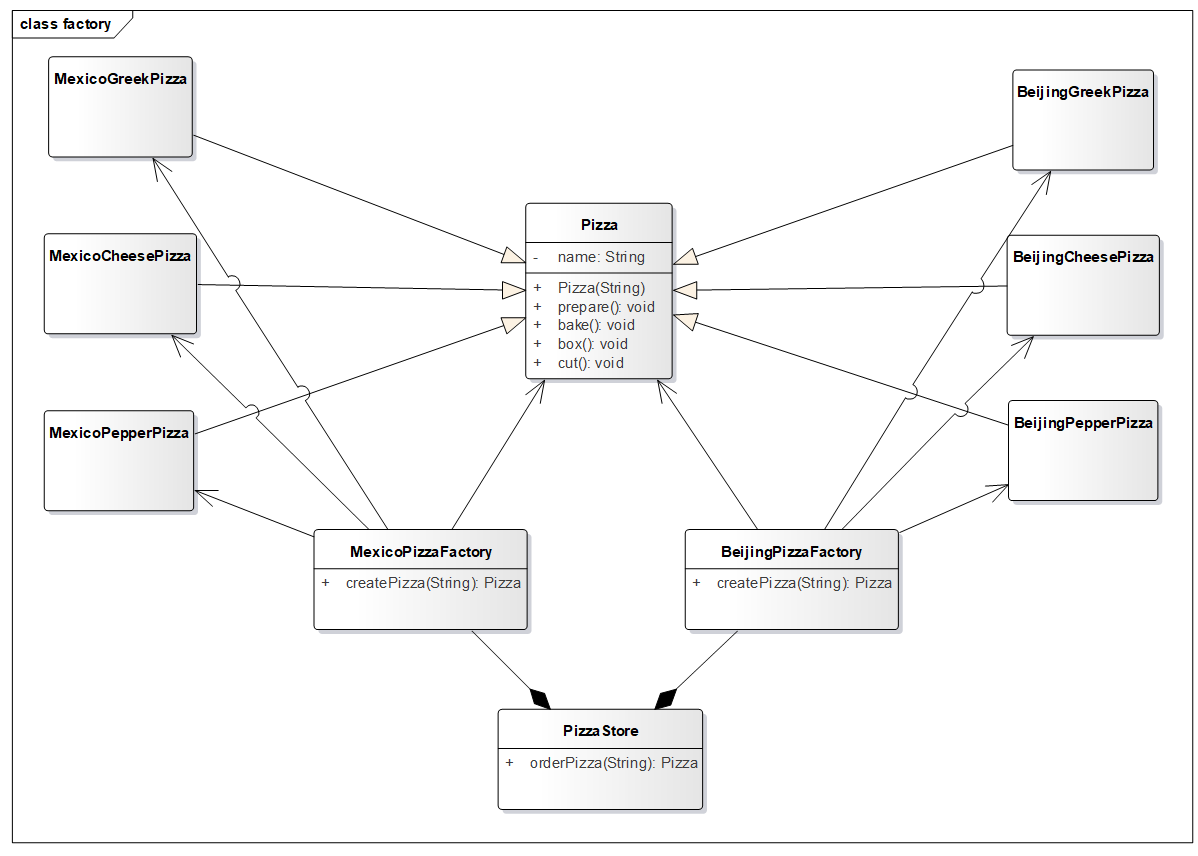
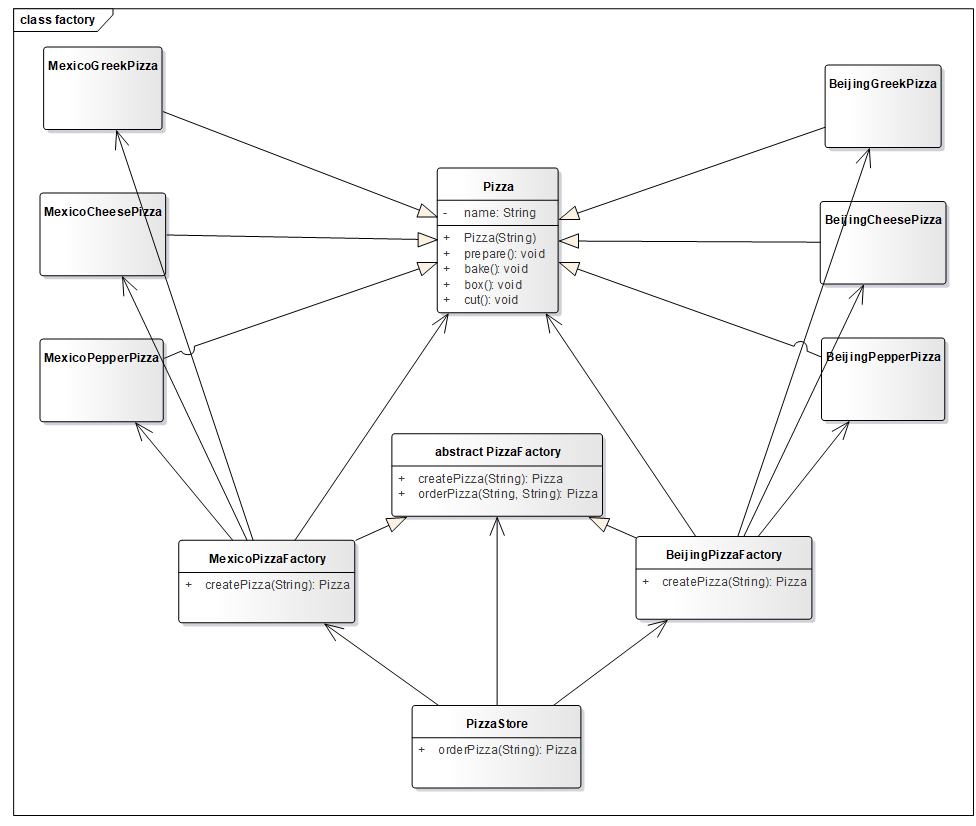
4.3.3 添加新风味! 各种口味的披萨我们已经会创建了,那么接下来在这基础之上再添加不同的风味,如墨西哥奶酪披萨,老北京胡椒披萨等。
方案一,制作多个工厂类组合到 PizzaStore 类中,不过这种方案缺陷同一开始传统代码一样,新增或减少多种风味都需要修改 PizzaStore 中的代码!
方案二,再加一层!这样无论如何修改风味,PizzaStore 中的代码都绝不会再变了。
披萨基类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public abstract class Pizza private String name; public Pizza (String name) this .name = name; } void prepare () System.out.println("准备" + name + "披萨的原材料..." ); } void bake () System.out.println("烘烤" + name + "披萨..." ); } void cut () System.out.println("切割" + name + "披萨..." ); } void box () System.out.println("打包" + name + "披萨..." ); } }
披萨实体类
1 2 3 4 5 public class BeijingCheesePizza extends Pizza public BeijingCheesePizza () super ("老北京风味奶酪" ); } }
1 2 3 4 5 public class BeijingGreekPizza extends Pizza public BeijingGreekPizza () super ("老北京风味希腊" ); } }
BeijingPizzaFactory 类,创建老北京风味的披萨。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class BeijingPizzaFactory public Pizza createPizza (String name) Pizza pizza = null ; switch (name){ case "希腊" : pizza = new BeijingGreekPizza(); break ; case "奶酪" : pizza = new BeijingCheesePizza(); break ; case "胡椒" : pizza = new BeijingPepperPizza(); break ; } return pizza; } }
MexicoPizzaFactory 类,创建墨西哥风味的披萨。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class MexicoPizzaFactory public Pizza createPizza (String name) Pizza pizza = null ; switch (name){ case "希腊" : pizza = new MexicoGreekPizza(); break ; case "奶酪" : pizza = new MexicoCheesePizza(); break ; case "胡椒" : pizza = new MexicoPepperPizza(); break ; } return pizza; } }
风味披萨工厂的工厂类,创建风味披萨工厂。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class PizzaFactory public Pizza createPizza (String style, String name) Pizza pizza = null ; switch (style){ case "墨西哥" : pizza = new MexicoPizzaFactory().createPizza(name); break ; case "老北京" : pizza = new BeijingPizzaFactory().createPizza(name); break ; } return pizza; } }
PizzaStore 测试类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class PizzaStore PizzaFactory pizzaFactory = new PizzaFactory(); public Pizza orderPizza (String style, String name) Pizza pizza = pizzaFactory.createPizza(style, name); if (pizza == null ){ return null ; } pizza.prepare(); pizza.bake(); pizza.cut(); pizza.box(); return pizza; } public static void main (String[] args) Scanner sc = new Scanner(System.in); PizzaStore pizzaStore = new PizzaStore(); while (true ){ String style = sc.next(); String name = sc.next(); Pizza pizza = pizzaStore.orderPizza(style, name); if (pizza == null ){ System.out.println("很抱歉,本店没有" + style + "风味" + name +"披萨" ); break ; } } } }
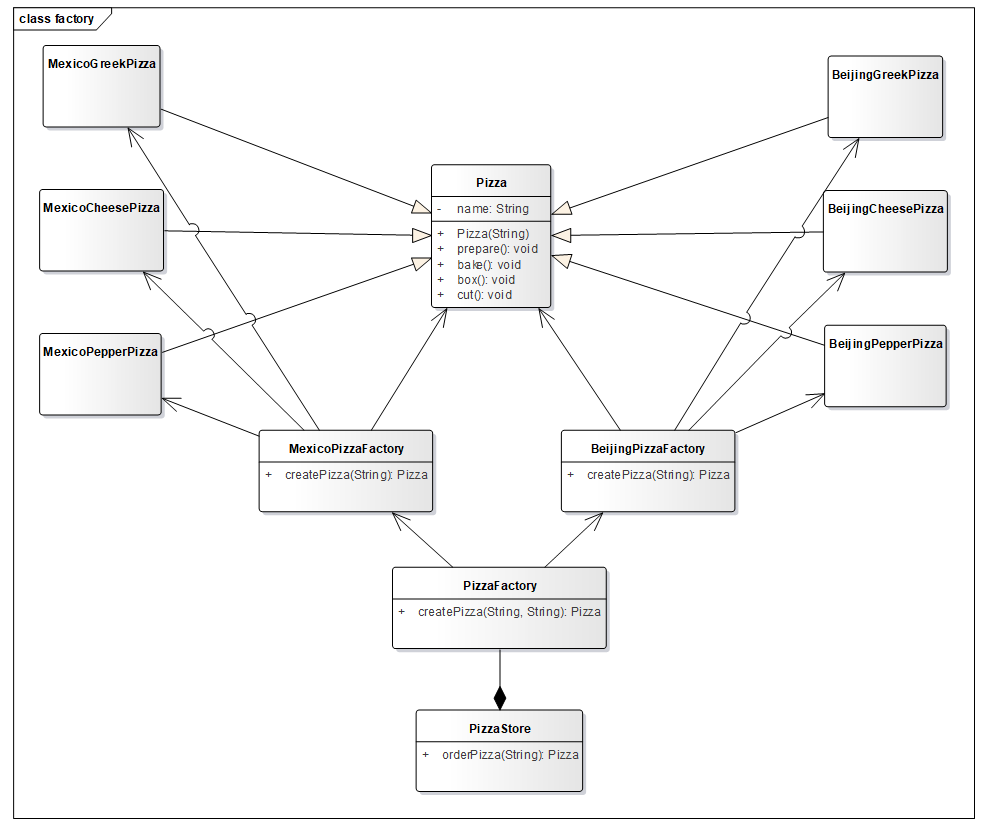
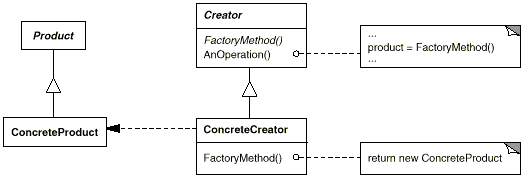
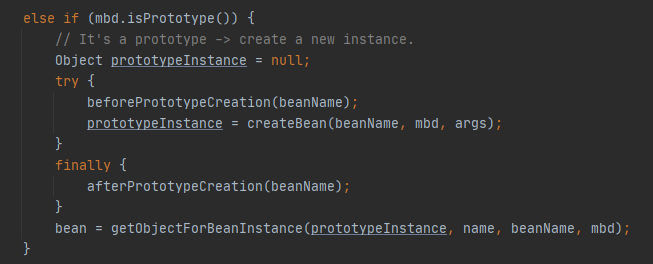
4.3.4 工厂方法模式 工厂方法模式: 定义了一个创建对象的抽象方法,由子类决定要实例化的类。工厂方法模式将对象的实例化推迟到子类。(这里将 orderPizza() 方法创建在工厂基类中,便于学习该模式效果)
工厂方法模式设计方案: 将披萨项目的实例化功能抽象成抽象方法,在不同的口味子类中具体实现。
披萨店 UML 如下。
工厂基类,createPizza() 方法等子类来实现,可以在orderPizza() 中先用起来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public abstract class PizzaFactory abstract Pizza createPizza (String name) public final Pizza orderPizza (String name) Pizza pizza = createPizza(name); if (pizza == null ){ return null ; } pizza.prepare(); pizza.bake(); pizza.cut(); pizza.box(); return pizza; } }
工厂子类,实现对象的实例化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class BeijingPizzaFactory extends PizzaFactory public Pizza createPizza (String name) Pizza pizza = null ; switch (name){ case "希腊" : pizza = new BeijingGreekPizza(); break ; case "奶酪" : pizza = new BeijingCheesePizza(); break ; case "胡椒" : pizza = new BeijingPepperPizza(); break ; } return pizza; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class MexicoPizzaFactory extends PizzaFactory public Pizza createPizza (String name) Pizza pizza = null ; switch (name){ case "希腊" : pizza = new MexicoGreekPizza(); break ; case "奶酪" : pizza = new MexicoCheesePizza(); break ; case "胡椒" : pizza = new MexicoPepperPizza(); break ; } return pizza; } }
PizzaStore 测试类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class PizzaStore private static PizzaFactory pizzaFactory; public static void main (String[] args) Scanner sc = new Scanner(System.in); while (true ){ Pizza pizza = null ; String style = sc.next(); String name = sc.next(); switch (style){ case "墨西哥" : pizzaFactory = new MexicoPizzaFactory(); break ; case "老北京" : pizzaFactory = new BeijingPizzaFactory(); break ; } pizza = pizzaFactory.orderPizza(name); if (pizza == null ){ System.out.println("很抱歉,本店没有" + style + "风味" + name +"披萨" ); break ; } } } }
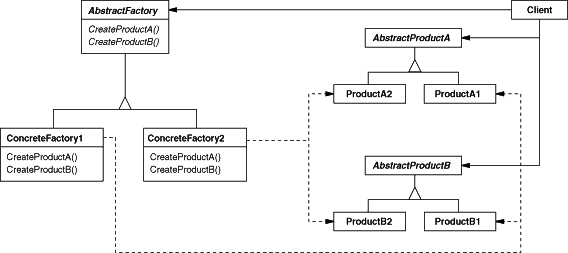
4.3.5 抽象工厂模式 抽象工厂模式提供一个接口,用于创建相关或依赖对象的家族,而不需要指定具体类。
抽象工厂允许客户使用抽象的接口来创建一组相关的产品,而不需要知道(或关心)实际产出的具体产品是什么。这样一来,客户就从具体的产品中被解耦。
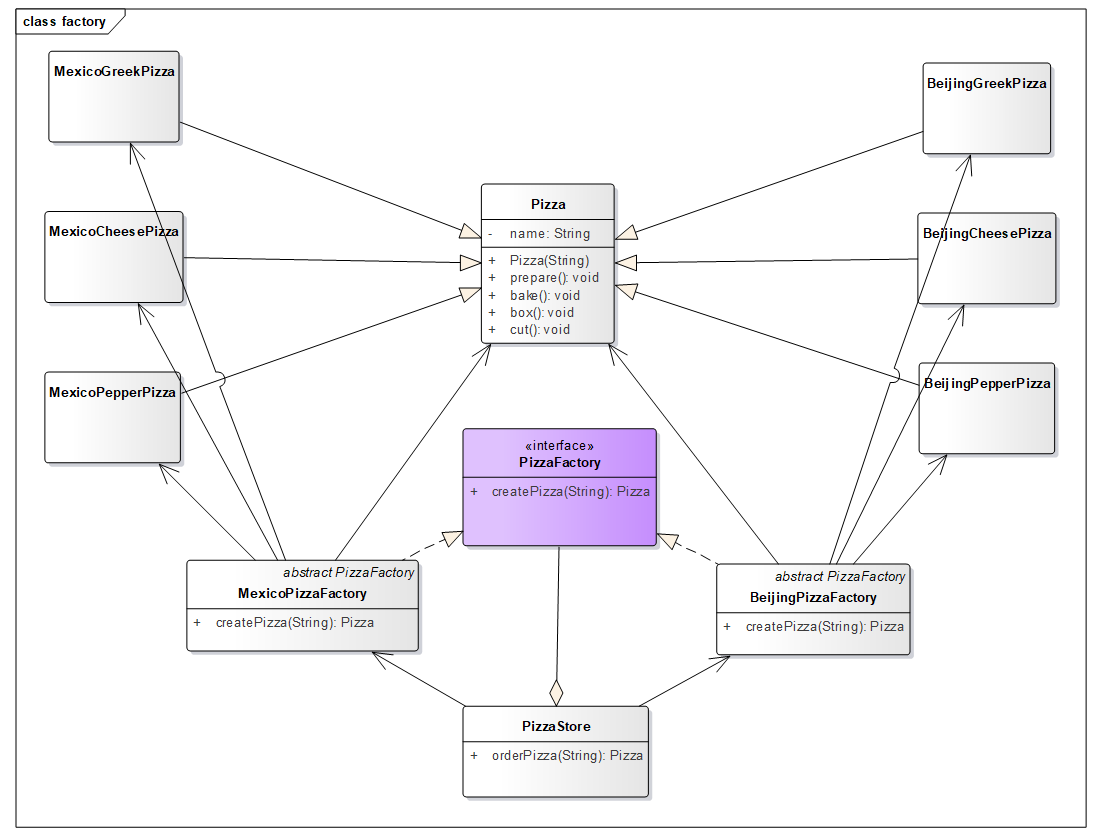
风味披萨店修改如下,为所有工厂添加抽象类(接口)。
抽象工厂类(接口)
1 2 3 public interface PizzaFactory Pizza createPizza (String name) ; }
实现工厂类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class MexicoPizzaFactory implements PizzaFactory public Pizza createPizza (String name) Pizza pizza = null ; switch (name){ case "希腊" : pizza = new MexicoGreekPizza(); break ; case "奶酪" : pizza = new MexicoCheesePizza(); break ; case "胡椒" : pizza = new MexicoPepperPizza(); break ; } return pizza; } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class PizzaStore private PizzaFactory pizzaFactory; private void setPizzaFactory (PizzaFactory pizzaFactory) this .pizzaFactory = pizzaFactory; } public Pizza orderPizza (String type, String name) switch (type){ case "墨西哥" : setPizzaFactory(new MexicoPizzaFactory()); break ; case "老北京" : setPizzaFactory(new BeijingPizzaFactory()); break ; } Pizza pizza = pizzaFactory.createPizza(name); pizza.prepare(); pizza.bake(); pizza.cut(); pizza.box(); return pizza; } public static void main (String[] args) Scanner sc = new Scanner(System.in); while (true ){ Pizza pizza = null ; String style = sc.next(); String name = sc.next(); PizzaStore pizzaStore = new PizzaStore(); pizza = pizzaStore.orderPizza(style, name); if (pizza == null ){ System.out.println("很抱歉,本店没有" + style + "风味" + name +"披萨" ); break ; } } } }
4.3.6 工厂方法模式 vs 抽象工厂模式
产品 vs 产品集
工厂方法模式一般用于生产一个产品。
抽象工厂模式一般用于生成一个产品家族。
继承 vs 组合
工厂方法模式依赖继承来决定生产什么产品,在工厂实现类中不仅有用于创建产品的方法(实现父类的抽象方法),还有其它方法。
因此,我们必须创建一个完整的工厂实现类来创建一个新的不同的产品,而不可能创建一个独立的用于生产产品的专用类。
而在抽象工厂模式中,有一个专门的类用于创建一系列相关的产品,它的子类工厂对象可以传递给使用它的客户端(组合)。由此,客户端可以获得一个不同的对象(工厂)来创建产品,而不是像工厂方法创建自己(例如使用 factoryMethod() 强制继承)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 abstract class Client public void anOperation () Product p = Factorymethod(); p.dosomething(); } abstract Product FactoryMethod () } class newclient extends Client public Product Factorymethod () return new specificProduct(); } } class Client private Factory factory; public client (Factory factory) this .factory = factory; } public void anOperation () Product p = factory.createProductA(); p.dosomething(); } } interface Factory Producta createProductA () ; Productb createProductB () ; }
方法 vs 对象
工厂方法仅仅只是个方法,但含有工厂方法的类并不只能创建产品,它还做其他的工作。
而抽象工厂唯一的任务就是创建一个产品家族。
4.3.7 单例模式在 JDK 中的应用 简单工厂应用
4.3.8 工厂模式小结 工厂模式就是将实例化对象的代码提取出来,放到一个类中统一管理和维护,达到和主项目的依赖关系的解耦,从而提高项目的扩展和可维护性。
4.4 原型模式 4.4.1 克隆羊问题 现在有一只羊,姓名为:tom,年龄为:1,颜色为:白色,请编写程序创建和 tom 羊属性完全相同的 10 只羊。
传统代码 如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class SheepClone public static void main (String[] args) Sheep sheep = new Sheep("tom" , 1 , "white" ); Sheep sheep1 = new Sheep(sheep.getName(), sheep.getAge(), sheep.getColor()); Sheep sheep2 = new Sheep(sheep.getName(), sheep.getAge(), sheep.getColor()); Sheep sheep3 = new Sheep(sheep.getName(), sheep.getAge(), sheep.getColor()); Sheep sheep4 = new Sheep(sheep.getName(), sheep.getAge(), sheep.getColor()); Sheep sheep5 = new Sheep(sheep.getName(), sheep.getAge(), sheep.getColor()); Sheep sheep6 = new Sheep(sheep.getName(), sheep.getAge(), sheep.getColor()); Sheep sheep7 = new Sheep(sheep.getName(), sheep.getAge(), sheep.getColor()); Sheep sheep8 = new Sheep(sheep.getName(), sheep.getAge(), sheep.getColor()); Sheep sheep9 = new Sheep(sheep.getName(), sheep.getAge(), sheep.getColor()); Sheep sheep10 = new Sheep(sheep.getName(), sheep.getAge(), sheep.getColor()); } }
优点 :
缺点 :
创建对象总是需要获取原始对象的属性,如果原对象有几十个属性呢?
总是需要重新初始化对象,而不是动态地获得对象运行时的状态,不够灵活。
4.4.2 克隆技术的使用 在 Java 中 Object 类是所有类的根类,Object 类提供了一个 clone() 方法,该方法可以将一个 Java 对象复制一份,但是需要实现一个接口 Cloneable,该接口表示该类能够复制且具有复制的能力,这就是原型模式。
Object 中的 clone() 方法。
1 2 protected native Object clone () throws CloneNotSupportedException
假如不实现 Cloneable 接口就调用 clone() 会怎么样呢?
1 2 3 4 5 6 7 8 9 10 11 public class Sheep private String name; private int age; private String color; @Override protected Object clone () throws CloneNotSupportedException return super .clone(); } }
测试如下,CloneNotSupportedException 不支持克隆异常。
1 2 3 4 Sheep sheep = new Sheep("tom" , 1 , "white" ); Sheep sheep1 = (Sheep) sheep.clone(); Exception in thread "main" java.lang.CloneNotSupportedException:
所以还是老老实实加上吧。
1 public class Sheep implements Cloneable
测试,clone() 会自动复制对象属性到新的对象上。
1 2 3 4 5 6 7 8 9 10 11 12 public class SheepClone public static void main (String[] args) throws CloneNotSupportedException Sheep sheep = new Sheep("tom" , 1 , "white" ); Sheep sheep1 = (Sheep) sheep.clone(); System.out.println(sheep.hashCode()); System.out.println(sheep1.hashCode()); System.out.println(sheep == sheep1); System.out.println(sheep.equals(sheep1)); } }
4.4.3 克隆羊的克隆羊朋友 有时克隆羊会觉得只有一个人很孤单,因此我们要给它找个朋友。
1 2 3 4 5 6 public class Sheep implements Cloneable private String name; private int age; private String color; private Sheep friend; }
测试,克隆羊朋友会不会克隆呢?
1 2 3 4 5 6 7 8 9 10 11 public class SheepClone public static void main (String[] args) throws CloneNotSupportedException Sheep sheep = new Sheep("tom" , 1 , "white" ); sheep.setFriend(new Sheep("friend" , 2 , "black" )); Sheep sheep1 = (Sheep) sheep.clone(); System.out.println(sheep.getFriend().hashCode()); System.out.println(sheep1.getFriend().hashCode()); System.out.println(sheep.getFriend() == sheep1.getFriend()); System.out.println(sheep.getFriend().equals(sheep1.getFriend())); } }
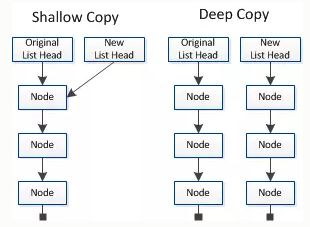
显然,这里克隆羊朋友只是复制了引用而已,俗称浅拷贝。
但浅拷贝虽然效率高了(对于引用类型只需要复制引用),但它也带来了另外的问题,如下述代码所示。
1 2 3 4 5 6 7 8 9 public class SheepClone public static void main (String[] args) throws CloneNotSupportedException Sheep sheep = new Sheep("tom" , 1 , "white" ); sheep.setFriend(new Sheep("friend" , 2 , "black" )); Sheep sheep1 = (Sheep) sheep.clone(); sheep.getFriend().setName("renamed friend" ); System.out.println(sheep1.getFriend().getName()); } }
当更改原克隆羊的克隆羊朋友名字时,新克隆羊的克隆羊朋友名字也发生了更改,有的时候我们并不希望看到这样!这就引出了深拷贝。
4.4.4 赋值 vs 浅拷贝 vs 深拷贝 赋值:
当我们把一个对象赋值给一个新的变量时,赋的其实是该对象的在栈中的地址,而不是堆中的数据 。也就是两个对象指向的是同一个存储空间,无论哪个对象发生改变,其实都是改变的存储空间的内容,因此,两个对象是联动的。
浅拷贝:
浅拷贝是按位拷贝对象,它会创建一个新对象 ,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值;如果属性是内存地址(引用类型),拷贝的就是内存地址 ,因此如果其中一个对象改变了这个地址,就会影响到另一个对象。即默认拷贝构造函数只是对对象进行浅拷贝复制(逐个成员依次拷贝),即只复制对象空间而不复制资源。
深拷贝:
而深拷贝则不同,它不仅将原对象的各个属性逐个复制出去,而且将原对象各个属性所包含的对象也依次采用深复制的方法递归复制 到新对象上。
4.4.5 实现深拷贝 方案一 :重写 clone() 方法
1 2 3 4 5 6 7 8 9 @Override protected Object clone () throws CloneNotSupportedException Sheep sheepClone = (Sheep) super .clone(); if (this .friend != null ){ sheepClone.setFriend((Sheep) this .friend.clone()); } return sheepClone; }
测试如下,这下原克隆羊的克隆羊朋友也被克隆成了一个新的对象(绕口令)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class SheepClone public static void main (String[] args) throws CloneNotSupportedException Sheep sheep = new Sheep("tom" , 1 , "white" ); sheep.setFriend(new Sheep("friend" , 2 , "friend" )); Sheep sheep1 = (Sheep) sheep.clone(); System.out.println(sheep.getFriend().hashCode()); System.out.println(sheep1.getFriend().hashCode()); System.out.println(sheep.getFriend() == sheep1.getFriend()); System.out.println(sheep.getFriend().equals(sheep1.getFriend())); System.out.println(sheep.getName().hashCode()); System.out.println(sheep1.getName().hashCode()); System.out.println(sheep.getName() == sheep1.getName()); System.out.println(sheep.getName().equals(sheep1.getName())); } }
缺点 :
每有一个引用类型就要单独进行一次 clone() 操作,非常麻烦!而且如果引用类型中的属性还有引用类型的话,就还得再写一层,所以这种方式也叫二重浅拷贝。
<% note success %>这里 Sheep 类的 name 是 String 类型的,虽然 String 虽然也是引用类型,但它并没有实现 Cloneable 接口,不能进行深拷贝,只能浅拷贝,因此地址都是一样的!<% endnote %>
但如果有一只克隆羊觉得它不需要朋友,它唯一的朋友就是自己。
1 2 3 4 5 6 7 8 9 10 11 public class SheepClone public static void main (String[] args) throws CloneNotSupportedException Sheep sheep = new Sheep("tom" , 1 , "white" ); sheep.setFriend(sheep); Sheep sheep1 = (Sheep) sheep.clone(); System.out.println(sheep.getFriend().hashCode()); System.out.println(sheep1.getFriend().hashCode()); System.out.println(sheep.getFriend() == sheep1.getFriend()); System.out.println(sheep.getFriend().equals(sheep1.getFriend())); } }
这时再进行 **clone()**,由于会不断进行递归,而且没有尽头!!!不一会儿就会抛出 StackOverFlowError 栈溢出错误,必须要避免这种情况,不要把引用指向自己!
方案二 :序列化 + 反序列化(要实现序列化接口)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class Sheep implements Cloneable , Serializable @Override protected Object clone () throws CloneNotSupportedException ByteArrayOutputStream bos = null ; ObjectOutputStream oos = null ; ByteArrayInputStream bis = null ; ObjectInputStream ois = null ; Sheep sheepClone = null ; try { bos = new ByteArrayOutputStream(); oos = new ObjectOutputStream(bos); oos.writeObject(this ); bis = new ByteArrayInputStream(bos.toByteArray()); ois = new ObjectInputStream(bis); sheepClone = (Sheep) ois.readObject(); }catch (Exception e){ System.out.println(e.getMessage()); return null ; } finally { try { ois.close(); bis.close(); oos.close(); bos.close(); } catch (IOException e) { e.printStackTrace(); } } return sheepClone; } }
测试如下,同样能很好地将引用类型进行深拷贝。
1 2 3 4 5 6 7 8 9 10 11 public class SheepClone public static void main (String[] args) throws CloneNotSupportedException Sheep sheep = new Sheep("tom" , 1 , "white" ); sheep.setFriend(new Sheep("friend" , 2 , "friend" )); Sheep sheep1 = (Sheep) sheep.clone(); System.out.println(sheep.getFriend().hashCode()); System.out.println(sheep1.getFriend().hashCode()); System.out.println(sheep.getFriend() == sheep1.getFriend()); System.out.println(sheep.getFriend().equals(sheep1.getFriend())); } }
而且由于不会使用递归进行深拷贝,即使引用类型指向自己也不会发生栈溢出的错误!
1 2 3 4 5 6 7 8 9 10 11 public class SheepClone public static void main (String[] args) throws CloneNotSupportedException Sheep sheep = new Sheep("tom" , 1 , "white" ); sheep.setFriend(sheep); Sheep sheep1 = (Sheep) sheep.clone(); System.out.println(sheep.getFriend().hashCode()); System.out.println(sheep1.getFriend().hashCode()); System.out.println(sheep.getFriend() == sheep1.getFriend()); System.out.println(sheep.getFriend().equals(sheep1.getFriend())); } }
4.4.6 原型模式在 Spring 中的应用 Spring 中可以配置 bean 的作用域是原型还是单例,默认单例。
1 <bean id ="user" class ="com.yqx.pojo.User" scope ="prototype" />
4.4.7 小结 原型模式(Prototype Pattern)是用于创建重复的对象,同时又能保证性能。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
这种模式是实现了一个原型接口,该接口用于创建当前对象的克隆。当直接创建对象的代价比较大时,则采用这种模式。例如,一个对象需要在一个高代价的数据库操作之后被创建。我们可以缓存该对象,在下一个请求时返回它的克隆,在需要的时候更新数据库,以此来减少数据库调用。
不过缺点就是,需要为每一个类都实现一个克隆方法,当然,这对一个全新的类来说不是很难,但对已有的类进行改造时,就需要修改其源代码,这违背了 ocp 原则!
4.5 建造者模式 4.5.1 盖房项目需求 1) 建房子过程:打地基,砌墙面,盖房顶。
2) 房子样式:瓦房,高楼,别墅等…
传统思路:
代码实现 ,盖房基类。
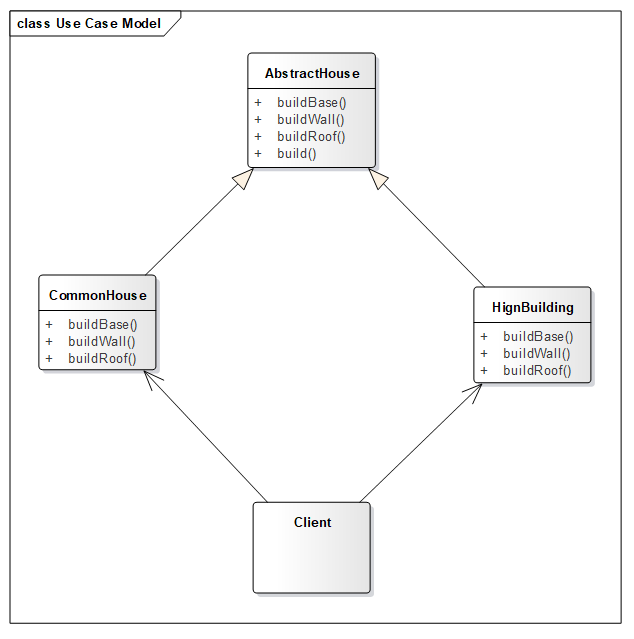
1 2 3 4 5 6 7 8 9 10 11 public abstract class AbstractHouse public abstract void buildBase () public abstract void buildRoof () public abstract void buildWall () public final void build () buildBase(); buildWall(); buildRoof(); } }
实现类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class CommonHouse extends AbstractHouse @Override public void buildBase () System.out.println("普通房打地基" ); } @Override public void buildRoof () System.out.println("普通房盖房顶" ); } @Override public void buildWall () System.out.println("普通房砌墙面" ); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class HighBuilding extends AbstractHouse @Override public void buildBase () System.out.println("高楼打地基" ); } @Override public void buildRoof () System.out.println("高楼盖房顶" ); } @Override public void buildWall () System.out.println("高楼砌墙面" ); } }
测试类
1 2 3 4 5 6 public class Client public static void main (String[] args) AbstractHouse house = new CommonHouse(); house.build(); } }
优点:
缺点 :
设计的程序结构过于简单,没有设计缓存层对象,程序的扩展和维护不好。
这种设计方案将产品(房子)和创建产品的过程(盖房)封装在一起,耦合性增强了。
改进 :
4.5.2 建造者模式 建造者模式(Builder Pattern)又叫生成器模式 ,是一种对象构建模式,它可以将复杂对象的建造过程抽象出来,使这个抽象过程的不同实现方法可以构造出不同表现(属性)的对象。
建造者模式是一步一步创建一个复杂的对象,它允许用户只通过指定复杂对象的类型和内容就可以构建它们,用户不需要知道内部的具体构建细节。
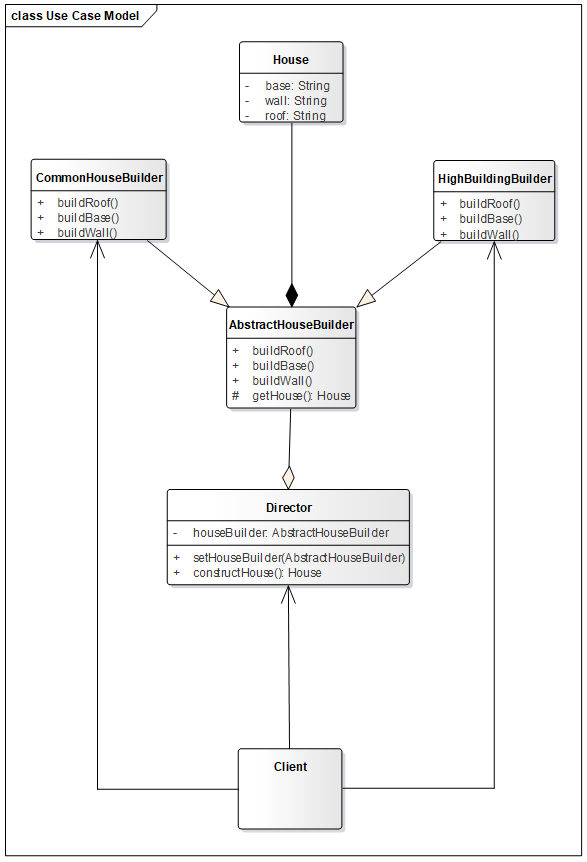
建造者模式拥有四个角色
Product(产品角色):一个具体的产品对象。
Builder(抽象建造者):创建 Product 对象的各个部件指定的 接口/抽象类 。
ConcreteBuilder(具体建造者):实现接口,构建和装配各个部件。
Director(指挥者):构建一个使用 Builder 接口的对象。它主要是用于创建一个复杂的对象。它主要有两个作用,一是:隔离了客户与对象的生产过程,二是:负责控制产品对象的生产过程。
UML 图如下
产品角色
1 2 3 4 5 6 7 8 @Data @AllArgsConstructor @NoArgsConstructor public class House private String base; private String roof; private String wall; }
抽象建造者
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public abstract class AbstractHouseBuilder protected House house = new House(); public abstract void buildBase () public abstract void buildRoof () public abstract void buildWall () public House build () return house; } }
具体建造者
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class CommonHouseBuilder extends AbstractHouseBuilder @Override public void buildBase () house.setBase("10m" ); System.out.println("普通房打地基" ); } @Override public void buildRoof () house.setRoof("red" ); System.out.println("普通房盖房顶" ); } @Override public void buildWall () house.setWall("10cm" ); System.out.println("普通房砌墙面" ); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class HighBuildingBuilder extends AbstractHouseBuilder @Override public void buildBase () house.setBase("20m" ); System.out.println("高楼打地基" ); } @Override public void buildRoof () house.setRoof("transparent" ); System.out.println("高楼盖房顶" ); } @Override public void buildWall () house.setWall("20cm" ); System.out.println("高楼砌墙面" ); } }
指挥者
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class HouseDirector private AbstractHouseBuilder houseBuilder; public HouseDirector (AbstractHouseBuilder houseBuilder) this .houseBuilder = houseBuilder; } public void setHouseBuilder (AbstractHouseBuilder houseBuilder) this .houseBuilder = houseBuilder; } public House constructHouse () houseBuilder.buildBase(); houseBuilder.buildWall(); houseBuilder.buildRoof(); return houseBuilder.build(); } }
客户端
1 2 3 4 5 6 7 8 public class Client public static void main (String[] args) HouseDirector houseDirector = new HouseDirector(new CommonHouseBuilder()); System.out.println(houseDirector.constructHouse()); houseDirector.setHouseBuilder(new HighBuildingBuilder()); System.out.println(houseDirector.constructHouse()); } }
优点 :
将一个复杂对象的创建过程封装起来。
允许对象通过多个步骤来创建,并且可以改变过程(这和只有一个步骤的工厂模式不同)。
向客户端隐藏产品内部的实现。
产品的实现可以被替换,因为用户只看到一个抽象的接口。
用途 :
缺点 :
和工厂模式相比,采用建造者模式创建对象的客户,需要具备更多的领域知识。
4.5.3 建造者模式在 JDK 中的应用 拿 StringBuilder 举例。
Appendable 接口定义了多个 append 方法(抽象方法),扮演抽象建造者的身份,定义了抽象方法。
AbstractStringBuilder 实现了 Appendable 接口,扮演者建造者的身份,但由于是抽象类,并不能实例化。
1 2 3 4 5 6 7 8 9 abstract class AbstractStringBuilder implements Appendable , CharSequence @Override public AbstractStringBuilder append (char c) ensureCapacityInternal(count + 1 ); value[count++] = c; return this ; } ... }
StringBuilder 充当了指挥者的角色,同时也是具体的建造者,建造方法的实现室友 AbstractStringBuilder 实现,而 StringBuilder 继承了 AbstractStringBuilder 。
1 2 3 4 5 6 7 8 9 10 public final class StringBuilder extends AbstractStringBuilder implements java .io .Serializable , CharSequence { @Override public StringBuilder append (char c) super .append(c); return this ; } ... }
4.5.4 抽象工厂模式 vs 建造者模式
4.5.5 小结
客户端使用程序不必知道产品内部组成的细节,将产品本身与产品的创建过程解耦,使得相同的创建过程可以创建不同的产品对象。
每一个具体建造者都相对独立,而与其他的具体建造者无关,因此可以很方便地替换具体建造者或增加新的具体建造者。用户使用不同的具体建造者就可以得到不同的产品对象。
可以更加精细地控制产品的创建过程,将复杂的创建过程分解在不同的方法中,使得创建过程更加清晰,也更方便使用程序来控制创建过程。
增加新的具体建造者无须修改原有类库的代码,指挥者类针对抽象建造者类编程,系统扩展方便,符合“开闭原则”。
建造者模式所创建的产品一般具有较多的共同点,其组成部分相似,如果产品之间的差异性很大,则不适合使用建造者模式,因此其使用范围受到一定的限制。
如果产品的内部变化复杂,可能会导致需要定义很多具体建造者类来实现这种变化,导致系统变得很庞大,因此在这种情况下,要考虑是否选择建造者模式。
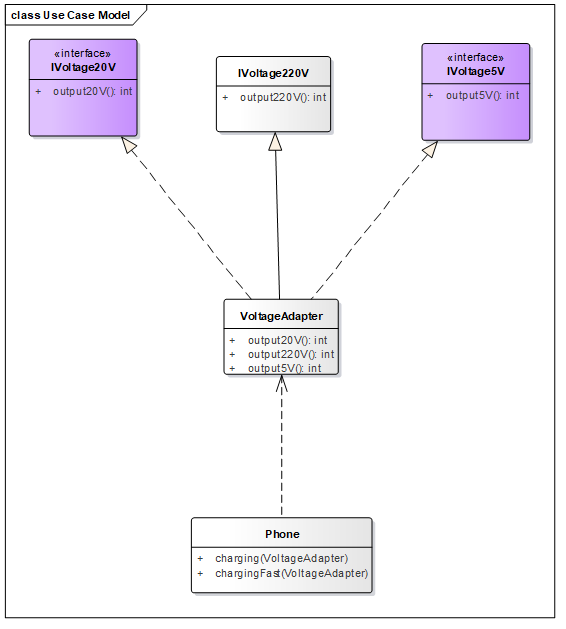
4.6 适配器模式 适配器模式将某个类的接口转换为客户端期望的另一个接口表示,主要目的是兼容性。让原本因接口不匹配的两个类可以协同工作,别名包装器。
适配器主要有三种实现方式:类适配器模式、对象适配器模式、接口适配器模式。
以生活中充电器的例子来说明适配器模式,充电器本身相当于 Adapter ,220V 交流电 相当于 src (被适配者),而我们的目标 dst 是 5V 直流电。
4.6.1 类适配器
220V,需要被适配的类
1 2 3 4 5 6 7 8 public class Voltage220V public int output220V () int src = 220 ; System.out.println("输出" + src + "V..." ); return src; } }
5V,适配的目标。
1 2 3 4 public interface IVoltage5V int output5V () }
20V,也是适配的目标。
1 2 3 4 public interface IVoltage20V int output20V () }
适配器,将 220V 交流电转化为各种直流电。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class VoltageAdapter extends Voltage220V implements IVoltage5V , IVoltage20V @Override public int output5V () int src = output220V(); int dst = src / 44 ; System.out.println("转换为" + dst + "V..." ); return dst; } @Override public int output20V () int src = output220V(); int dst = src/11 ; System.out.println("转换为" + dst + "V快充..." ); return dst; } }
手机,使用目标的类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class Phone public void charging (IVoltage5V iVoltage5V) if (iVoltage5V.output5V() == 5 ){ System.out.println("电压为5V,可以充电~~" ); }else { System.out.println("电压不为5V,不能充电~~" ); } } public void chargingFast (IVoltage20V iVoltage20V) if (iVoltage20V.output20V() == 20 ){ System.out.println("电压为20V,可以进行快充~~" ); }else { System.out.println("电压不为20V,不能进行快充,将自动转换为普通充电~~" ); charging((VoltageAdapter)iVoltage20V); } } }
测试类,调用充电方法只需要传入 VoltageAdapter 适配器对象即可。
1 2 3 4 5 6 public class AdapterTest public static void main (String[] args) new Phone().charging(new VoltageAdapter()); new Phone().chargingFast(new VoltageAdapter()); } }
优点 :
由于继承了 src 类,所以它可以根据需求重写 src 类的方法,使得 Adapter 的灵活性增强。
缺点 :
Java 是单继承机制,所以类适配器需要继承 src 类从这一点来说算是一个缺点,因为这要求 dst 必须是接口,有一定的局限性。
src 类中的方法在 Adapter 中都会暴露出来,增加使用的成本。
4.6.2 对象适配器 不是采用继承的方式,而是使用组合(聚合)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class VoltageAdapter implements IVoltage5V , IVoltage20V Voltage220V voltage220V = new Voltage220V(); @Override public int output5V () int src = voltage220V.output220V(); int dst = src / 44 ; System.out.println("转换为" + dst + "V..." ); return dst; } @Override public int output20V () int src = voltage220V.output220V(); int dst = src/11 ; System.out.println("转换为" + dst + "V快充..." ); return dst; } }
对象适配器和类适配器其实是同一种思想,只不过实现方式不同。根据合成复用原则,使用组合替代继承,使用成本更低也更灵活,解决了类适配器必须继承 src 的局限性问题,也不再要求 dst 必须是接口。
4.6.3 接口适配器 实现接口就需要实现其中的所有方法,但很多时候我们只需要使用到其中一两个方法而已,再重写所有方法就显得有些多此一举了,这也就引出了接口适配器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 new MouseListener() { @Override public void mouseClicked (MouseEvent e) } @Override public void mousePressed (MouseEvent e) } @Override public void mouseReleased (MouseEvent e) } @Override public void mouseEntered (MouseEvent e) } @Override public void mouseExited (MouseEvent e) } } new MouseAdapter(){ @Override public void mouseClicked (MouseEvent e) super .mouseClicked(e); } };
不过接口适配器并不是什么很高大上的思想,只是加了一层抽象类来对方法进行空实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 public abstract class MouseAdapter implements MouseListener , MouseWheelListener , MouseMotionListener public void mouseClicked (MouseEvent e) public void mousePressed (MouseEvent e) public void mouseReleased (MouseEvent e) public void mouseEntered (MouseEvent e) public void mouseExited (MouseEvent e) public void mouseWheelMoved (MouseWheelEvent e) public void mouseDragged (MouseEvent e) public void mouseMoved (MouseEvent e) }
接口
1 2 3 4 5 6 public interface Interface void m1 () void m2 () void m3 () void m4 () }
抽象类空实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public abstract class AbsAdapter implements Interface @Override public void m1 () } @Override public void m2 () } @Override public void m3 () } @Override public void m4 () } }
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public static void main (String[] args) new AbsAdapter(){ @Override public void m1 () super .m1(); } }; new Interface(){ @Override public void m1 () } @Override public void m2 () } @Override public void m3 () } @Override public void m4 () } }; }
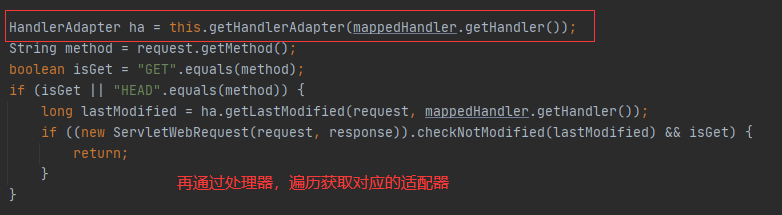
4.6.4 适配器模式在 Spring Mvc中的应用
可能看着会觉得多此一举,一开始就获取了处理器,为什么不直接调用它的方法呢?这是因为适配器调用处理器的方法可以添加适配功能 使得被使用者所需要。
Spring 定义了一个适配接口,使得每一种 Controller 都有一个对应的适配器实现类
适配器代替 Controller 执行响应的方法
扩展 Controller 时,只需要增加一个适配器的类就完成了 SpringMVC 的扩展。
4.6.5 模拟 HandlerAdapter 的实现 Controller 处理器类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public interface Controller } class HttpController implements Controller public void doHttpHandler () System.out.println("http..." ); } } class SimpleController implements Controller public void doSimpleHandler () System.out.println("simple..." ); } } class AnnotationController implements Controller public void doAnnotationHandler () System.out.println("annotation..." ); } }
Adapter 适配器类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 public interface HandlerAdapter boolean supports (Object handler) void handle (Object handler) } class HttpAdapter implements HandlerAdapter @Override public boolean supports (Object handler) return handler instanceof HttpController; } @Override public void handle (Object handler) ((HttpController)handler).doHttpHandler(); } } class SimpleAdapter implements HandlerAdapter @Override public boolean supports (Object handler) return handler instanceof SimpleController; } @Override public void handle (Object handler) ((SimpleController)handler).doSimpleHandler(); } } class AnnotationAdapter implements HandlerAdapter @Override public boolean supports (Object handler) return handler instanceof AnnotationController; } @Override public void handle (Object handler) ((AnnotationController)handler).doAnnotationHandler(); } }
DispatcherServlet 分发器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class DispatcherServlet public static List<HandlerAdapter> handlerAdapters = new ArrayList<>(); static { handlerAdapters.add(new AnnotationAdapter()); handlerAdapters.add(new SimpleAdapter()); handlerAdapters.add(new HttpAdapter()); } public void doDispatch (Controller controller) HandlerAdapter adapter = getHandler(controller); adapter.handle(controller); } public HandlerAdapter getHandler (Controller controller) for (HandlerAdapter handlerAdapter : handlerAdapters) { if (handlerAdapter.supports(controller)){ return handlerAdapter; } } return null ; } public static void main (String[] args) DispatcherServlet servlet = new DispatcherServlet(); servlet.doDispatch(new HttpController()); } }
4.6.6 小结
类适配器:以类给到,在 Adapter 中,就是将 src 当做类,继承 。
对象适配器:以对象给到,在 Adapter 中,就是将 src 当做对象,持有 。
接口适配器:以接口给到,在 Adapter 中,就是将 src 当做接口,实现 。
Adapter 模式最大的作用还是将原本不兼容的接口融合在一起工作。
实际开发中,实现起来不拘泥于以上三种经典方式。
4.7 桥接模式 4.7.1 基本介绍 1) 桥接模式(Bridge)是指:将实现 和抽象放在两个不同的类层次中,使两个层次可以独立改变。
2) 桥接模式是一种结构型设计模式。
3) 桥接模式基于类的最小设计原则,通过使用封装、聚合及继承等行为让不同的类承担不同的职责。它的主要特点是把抽象 与实现 分离开来,从而可以保持各部分的独立性以及对他们的功能拓展。
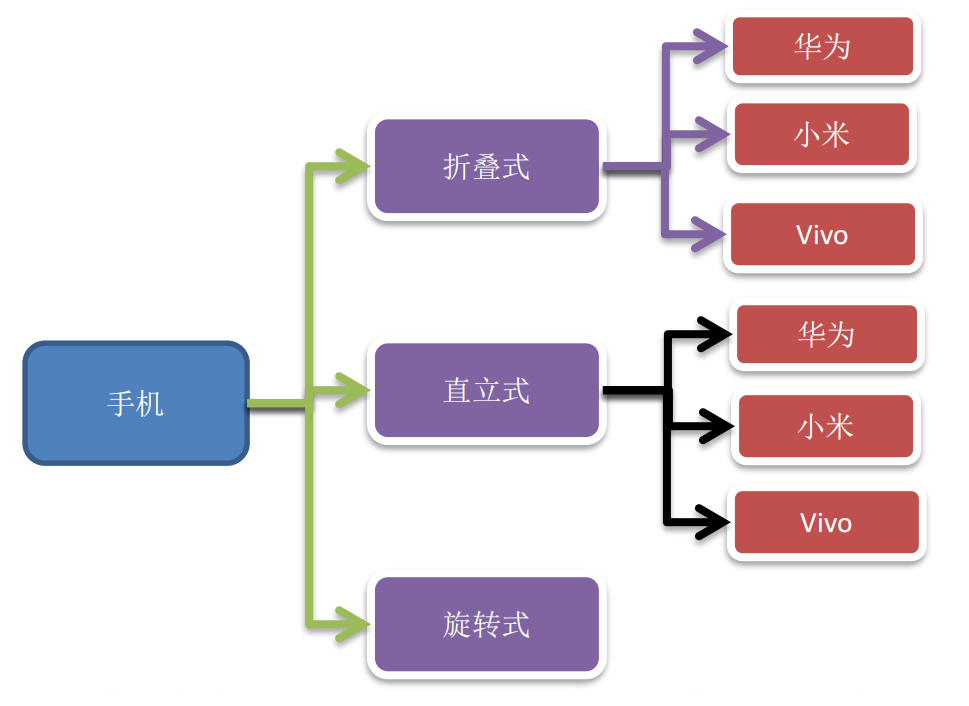
4.7.2 手机拓展问题 使用桥接模式改进传统方式,让程序具有更好的拓展性,利于程序维护。
传统方式需要 m(手机样式) * n(手机品牌) 个类,极易产生类爆炸的问题,而且每新增一个手机样式就又要增加 n 个类,拓展极其繁琐。
而采用了桥接模式之后,可以将 m * n 降为 m + n,平方降线性。
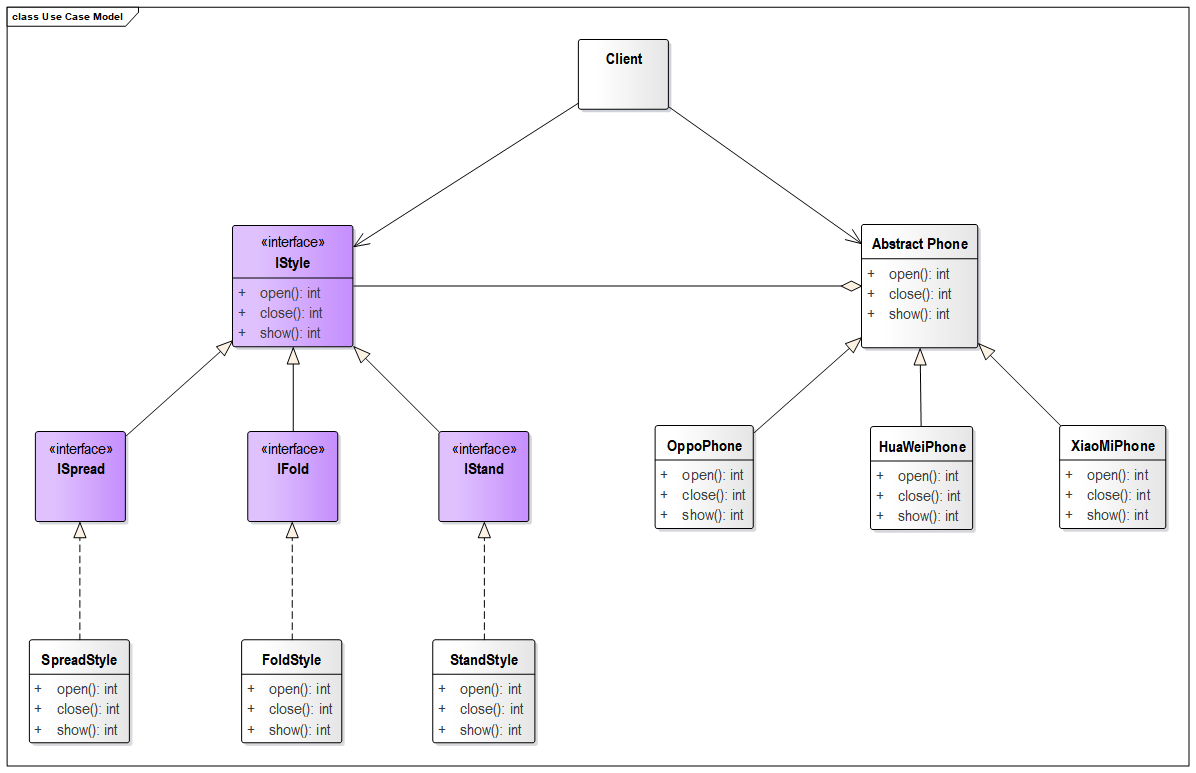
4.7.3 代码实现 UML 图如下
样式基类
1 2 3 4 5 public interface IStyle void show () void open () void close () }
样式接口类(此处可以省略)
1 2 3 4 5 6 7 8 public interface IFold extends IStyle } public interface ISpread extends IStyle } public interface IStand extends IStyle }
样式实体类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class FoldStyle implements IFold @Override public void show () System.out.println("手机折叠" ); } @Override public void open () System.out.println("折叠手机开机" ); } @Override public void close () System.out.println("折叠手机关机" ); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class SpreadStyle implements ISpread @Override public void show () System.out.println("手机旋转" ); } @Override public void open () System.out.println("旋转手机开机" ); } @Override public void close () System.out.println("旋转手机关机" ); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class StandStyle implements IStand @Override public void show () System.out.println("手机直立" ); } @Override public void open () System.out.println("直立手机开机" ); } @Override public void close () System.out.println("直立手机关机" ); } }
手机抽象类,聚合样式基类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public abstract class Phone private IStyle stylePhone; public Phone (IStyle stylePhone) this .stylePhone = stylePhone; } protected void show () stylePhone.show(); } protected void open () stylePhone.open(); } protected void close () stylePhone.close(); } }
手机实体类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class HuaWeiPhone extends Phone public HuaWeiPhone (IStyle stylePhone) super (stylePhone); } @Override protected void show () System.out.println("华为手机~" ); super .show(); } @Override protected void open () System.out.println("华为手机~" ); super .open(); } @Override protected void close () System.out.println("华为手机~" ); super .open(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class OppoPhone extends Phone public OppoPhone (IStyle stylePhone) super (stylePhone); } @Override protected void show () System.out.println("Oppo手机~" ); super .show(); } @Override protected void open () System.out.println("Oppo手机~" ); super .open(); } @Override protected void close () System.out.println("Oppo手机~" ); super .open(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class XiaoMiPhone extends Phone public XiaoMiPhone (IStyle stylePhone) super (stylePhone); } @Override protected void show () System.out.println("小米手机~" ); super .show(); } @Override protected void open () System.out.println("小米手机~" ); super .open(); } @Override protected void close () System.out.println("小米手机~" ); super .open(); } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 public class PhoneTest public static void main (String[] args) Phone phone1 = new HuaWeiPhone(new SpreadStyle()); phone1.open(); Phone phone2 = new OppoPhone(new FoldStyle()); phone2.show(); Phone phone3 = new XiaoMiPhone(new StandStyle()); phone3.close(); } }
输出结果
1 2 3 4 5 6 华为手机~ 旋转手机开机 Oppo手机~ 手机折叠 小米手机~ 直立手机开机
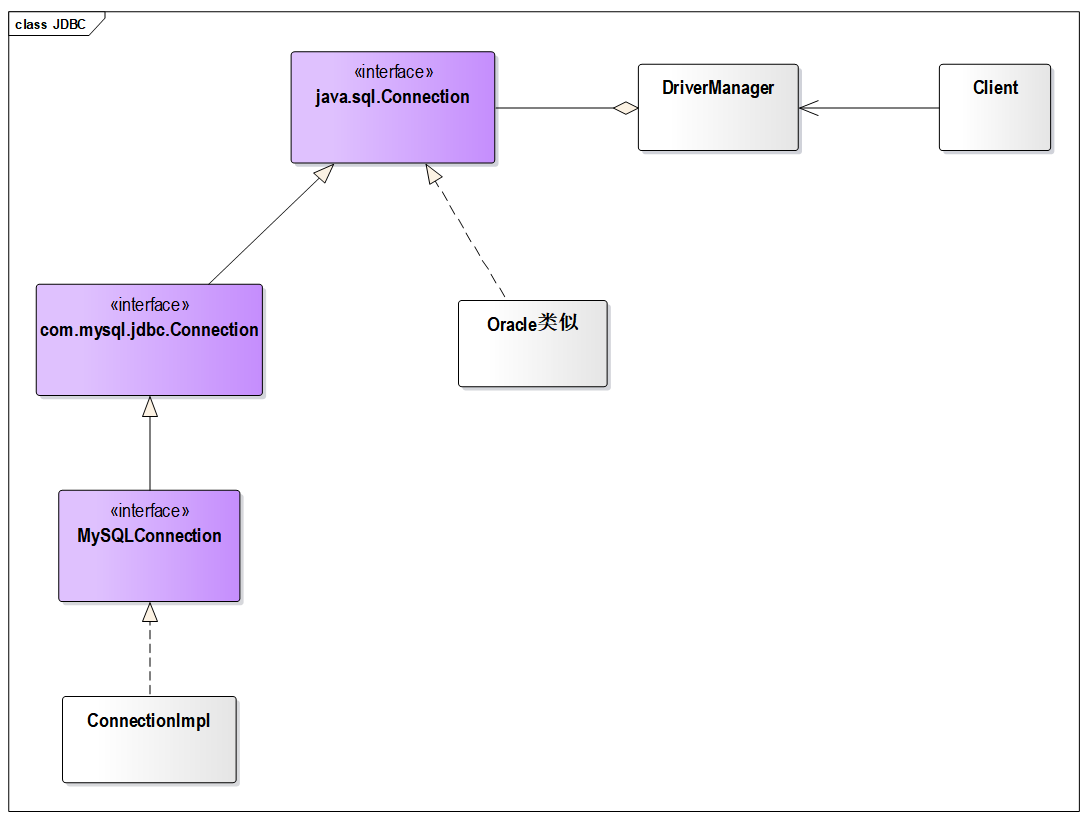
4.7.4 桥接模式在 JDBC 的运用 在 JDBC 中并不是真正的桥接模式,正如你所看到的,DriverManager 直接就是实体类了,并不是抽象类也没有子类,但具体思想还是一样的。
4.7.5 桥接模式适用场景
对于那些不希望适用继承或因为多层次继承而导致系统类的个数剧增加的系统,桥接模式尤为适用。
常见的应用场景
JDBC 驱动程序
银行转账系统
转账分类:网上转账,柜台转账,ATM转账。
转账用户类型:普通用户,银行卡用户,VIP 用户。
消息管理
消息类型:即时消息,延时消息。
消息分类:手机短信,邮件消息,qq 消息。
4.7.6 小结
桥接模式实现了抽象和实现部分的分离,从而极大的提供了系统的灵活性,让抽象部分和实现部分独立开来,这有助于系统进行分层设计,从而产生更好的结构化系统。
对于系统的高层部分,只需要知道抽象部分和实现部分的接口就行了,其它的部分由具体业务来完成。
桥接模式替代多层继承方案,有效减少了子类的个数,降低系统的管理和维护成本。
桥接模式的引入增加了系统的理解和设计难度,由于聚合关联关系建立在抽象层,要求开发者针对抽昂进行设计和编程。
桥接模式要求正确识别出系统中两个独立变化的维度,因此其使用范围有一定的局限性,即需要有这样的应用场景。