一、MySQL 入门
MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System)应用软件之一。
1、什么是数据库?
数据库(DataBase,简称DB)
概念:长期存放在计算机内,有组织,可共享的大量数据的集合,是一个数据“仓库”。
作用:保存,并能安全管理数据(增删改查等),减少冗余…
数据库总览
- 关系型数据库(SQL)
- MySQL,Oracle,SQL Server,SQLite,DB2…
- 关系型数据库通过外键关联来建立表与表之间的关系。
- 非关系型数据库(NOSQL,Not Only SQL)
- Redis,MongoDB…
- 非关系型数据库通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定。
2、什么是 DBMS?
数据库管理系统(DataBase Management System)
数据库管理软件,科学组织和存储数据,高效地获取和维护数据。
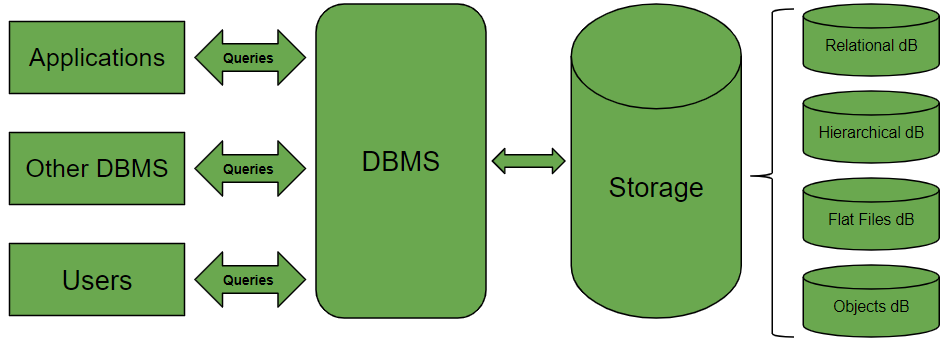
不那么严格的话,MySQL也算是一个数据库管理系统。
3、MySQL简介

概念:是现在流行的、开源的、免费的、关系型数据库。
历史:由瑞典MySQL AB公司开发,目前属于 Oracle 旗下产品。
特点:
- MySQL 是开源的,目前隶属于 Oracle 旗下产品。
- MySQL 支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL 使用标准的 SQL 数据语言形式。
- MySQL 可以运行于多个系统上,并且支持多种语言。这些编程语言包括 C、C++、Python、Java、Perl、PHP、Eiffel、Ruby 和 Tcl 等。
- MySQL 对PHP有很好的支持,PHP 是目前最流行的 Web 开发语言。
- MySQL 支持大型数据库,支持 5000 万条记录的数据仓库,32 位系统表文件最大可支持 4GB,64 位系统支持最大的表文件为8TB。
- MySQL 是可以定制的,采用了 GPL 协议,你可以修改源码来开发自己的 MySQL 系统。
4、安装MySQL
这里建议使用压缩版,安装快,方便,不复杂。
exe 可执行文件安装 MySQL 谁用谁知道,卸载是真的麻烦,┭┮﹏┭┮。
mysql5.7 64位下载地址:
https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.19-winx64.zip
安装步骤
1、下载后得到zip压缩包.
2、解压到自己想要安装到的目录,此处我解压到的是 D:\Environment\mysql-5.7.19
3、添加环境变量:我的电脑->属性->高级->环境变量
1 | 选择PATH,在其后面添加: 你的mysql 安装文件下面的bin文件夹 |
4、在 bin 文件夹下创建 my.ini 配置文件
1 | [mysqld] |
5、启动管理员模式下的 CMD,并将路径切换至 mysql 下的 bin 目录,然后输入 mysqld –install (安装mysql)
6、再输入 mysqld –initialize-insecure –user=mysql 初始化数据文件
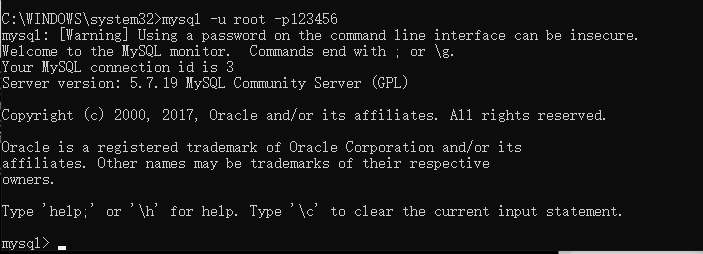
7、然后再次启动 mysql(net start mysql) 然后用命令 mysql –u root –p 进入 mysql 管理界面(密码暂时为空)
8、进入界面后更改root密码
1 | update mysql.user set authentication_string=password('123456') where user='root' and Host = 'localhost'; |
9、刷新权限
1 | flush privileges; |
10、修改 my.ini文件删除最后一句skip-grant-tables
11、重启mysql即可正常使用
1 | net stop mysql |
12、连接上测试出现以下结果就安装好了
1 | update user set password=password('123456')where user='root'; # 修改密码 |
二、基本概念
1、数据类型
数值类型
MySQL 支持所有标准 SQL 数值数据类型。
关键字INT是INTEGER的同义词,关键字DEC是DECIMAL的同义词。
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 Bytes | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 Bytes | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 Bytes | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 Bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 Bytes | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 Bytes | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 Bytes | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
日期类型
每个时间类型有一个有效值范围和一个”零”值,当指定不合法的MySQL不能表示的值时使用”零”值。
| 类型 | 大小 ( bytes) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01 ~ 9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | ‘-838:59:59’ ~ ‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901 ~ 2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00~2038结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
字符串类型
字符串类型指 CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM 和 SET。
| 类型 | 大小(字节) | 用途 |
|---|---|---|
| CHAR | 0 ~ 255 | 定长字符串 |
| VARCHAR | 0 ~ 65535 | 变长字符串 |
| TINYBLOB | 0 ~ 255 | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0 ~ 255 | 短文本字符串 |
| BLOB | 0 ~ 65 535 | 二进制形式的长文本数据 |
| TEXT | 0 ~ 65 535 | 长文本数据 |
| MEDIUMBLOB | 0 ~ 16 777 215 | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0 ~ 16 777 215 | 中等长度文本数据 |
| LONGBLOB | 0 ~ 4 294 967 295 | 二进制形式的极大文本数据 |
| LONGTEXT | 0 ~ 4 294 967 295 | 极大文本数据 |
注意:char(n) 和 varchar(n) 中括号中 n 代表字符的个数,并不代表字节个数,比如 CHAR(30) 就可以存储 30 个字符。
CHAR 和 VARCHAR 类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
BLOB 是一个二进制大对象,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。
有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。
NULL 值
- 理解为”没有值”或”未知值”
- 不要用 NULL 进行算术运算,结果仍为 NULL,没有意义
2、数据字段属性

Unsigned
- 无符号的
- 声明该数据列不允许负数
Zerofill
- 不足的位数用0来填充,例如int(3),5则为005
Auto_InCrement
- 自动增长的,每添加一条数据,自动在上一个记录数上加1(默认)
- 通常用于设置
主键,且为整数类型 - 可定义起始值和步长
- 起始值设置:AUTO_INCREMENT = 100,只影响当前表。
- 步长设置:SET @@auto_increment_increment = 5,影响所有使用自增的表。
NULL 和 NOTE NULL
- 默认为 NULL,即没有插入该列的数值。
- 如果设置为 NOT NULL,则该列必须有值。
DEFAULT
- 用于设置默认值
- 例如,性别字段,默认为”男”,若无指定该列的值,则默认为”男”。
3、数据表引擎
MySQL的数据表的类型 : MyISAM , InnoDB , HEAP , BOB , CSV等…
常见的 MyISAM 与 InnoDB 类型:
| 名称 | MyISAM | InnoDB |
|---|---|---|
| 事务处理 | 不支持 | 支持 |
| 数据行锁定 | 不支持 | 支持 |
| 外键约束 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
| 表空间大小 | 较小 | 约为 MyISAM 两倍 |
适用场合:
- MyISAM:节约空间,速度较快。
- InnoDB:安全性,事务处理及多用户操作数据表。
4、数据表的物理存储
MySQL 数据表以文件方式存储在磁盘中
- 包括表文件,数据文件,以及数据库的选项文件
- 位置:MySQL\data,目录名对应数据库名,该目录下文件名对应数据表
InnoDB

- .frm 文件 – 表结构定义文件
- .idb 文件 – MySQL数据文件、索引文件
InnoDB 类型数据表只有一个 *.frm 文件(不算 .idb 备份文件), 以及上一级目录的 ibdata1文件。
MyISAM

- . frm – 表结构定义文件
- . MYD – 数据文件 ( data )
- . MYI – 索引文件 ( index )
5、字符集
字符集是一套符合和编码,校验规则(collation)是在字符集内用于比较字符的一套规则,即字符集的排序规则。MySQL可以使用各种字符集和检验规则来组织字符。
MySQL服务器可以支持多种字符集,在同一台服务器,同一个数据库,甚至同一个表的不同字段都可以指定使用不同的字符集,相比oracle等其他数据库管理系统,在同一个数据库只能使用相同的字符集,MySQL明显存在更大的灵活性。
每种字符集都可能有多种校对规则,并且都有一个默认的校对规则,并且每个校对规则只是针对某个字符集,和其他的字符集没有关系。
而 MySQL 默认的字符集使用的是 Latin1,会导致中文乱码!因此需要为数据库、数据表、甚至数据列显式设定不同的字符集。或者在 my.ini 中修改默认的字符集。
1 | character-set-server = utf8 |
三、基本操作
1、数据库
1 | 创建数据库 : create database [if not exists] 数据库名; |
2、创建数据表
1 | -- 目标 : 创建一个school数据库 |
3、修改数据表
1 | ALTER TABLE student RENAME AS student1 -- 修改表名 |
可以使用```来包裹标识符,以避免和关键字重名!
四、外键
如果公共关键字在一个关系中是主关键字,那么这个公共关键字被称为另一个关系的外键。由此可见,外键表示了两个关系之间的相互联系。以另一个关系的外键作为主关键字的表称为主表,具有此外建的表被称为主表的从表。
在实际操作中,将一个表的值放入第二个表来表示关联,所使用的的值是第一个表的主键值(在必要时可包括复合主键值)。此时,第二个表中保存这些值的属性称为外键(foreign key)。
外键可以保持数据一致性,完整性,主要目的是约束存储在外键表中的数据。使两张表形成关联,外键只能引用主表中的列的值或使用空值。
1、建表时指定外键约束
1 | CREATE TABLE student ( |
注意事项
- 关联的两张表引擎必须相同
- 外键名不能重复
- 关联的两个类型必须相同
2、建表后添加外键
1 | ALTER TABLE `study`.`student` ADD CONSTRAINT `FK_tid` FOREIGN KEY (`tid`) REFERENCES `study`.`teacher`(`id`); |
3、删除外键
1 | -- 删除外键 |
以上的操作都是物理外键,数据库级别的外键,我们不建议使用!(避免数据库过多造成困扰,了解即可!)
最佳实践
- 数据库就是单纯的表,只用来存数据,只有行(数据)和列(字段)
- 我们想使用多张表的数据,想使用外键一般使用程序去实现
五、DML
数据库意义:数据存储、数据管理
管理数据库数据方法:
- 通过 SQLyog 等管理工具管理数据库数据
- 通过 DML 语句管理数据库数据
DML 语言:Data Manipulaiton Language,数据操作语言
- 用于操作数据库对象中所包含的数据
- 包括:
- INSERT(添加数据语句)
- UPDATE(更新数据语句)
- DELETE(删除数据语句)
1、INSERT
语法:
1 | INSERT INTO 表名[(字段1,字段2,字段3,...)] VALUES('值1','值2','值3'),('值1','值2','值3')... |
注意 :
- 字段或值之间用英文逗号隔开 .
- ‘ 字段1,字段2…’ 该部分可省略 , 但添加的值务必与表结构,数据列,顺序相对应,且数量一致 .
- 可同时插入多条数据 , values 后用英文逗号隔开 .
2、UPDATE
语法:
1 | UPDATE 表名 SET column_name=value [column_name2=value2,...] [WHERE condition]; |
注意 :
- column_name 为要更改的数据列
- value 为修改后的数据 , 可以为变量 , 具体指 , 表达式或者嵌套的SELECT结果
- condition 为筛选条件 , 如不指定则修改该表的所有列数据
3、DELETE
语法:
1 | DELETE FROM 表名 [WHERE condition]; |
注意:condition为筛选条件 , 如不指定则删除该表的所有列数据
1 | -- 删除id为5的数据 |
4、TRUNCATE
用于完全清空表数据 , 但表结构 , 索引 , 约束等不变 。
语法:
1 | TRUNCATE [TABLE] table_name; |
注意:区别于DELETE命令
相同 : 都能删除数据 , 不删除表结构 , 但 TRUNCATE 速度更快
不同 :
- 使用 TRUNCATE TABLE 重新设置 AUTO_INCREMENT 计数器
- 使用 TRUNCATE TABLE 不会对事务有影响
1 | -- 创建一个测试表 |
拓展:使用DELETE清空不同引擎的数据库表数据.重启数据库服务后
InnoDB : 自增列从初始值重新开始 (存储在内存中,断电即失)
MyISAM : 自增列依然从上一个自增数据基础上开始 (存在文件中,不会丢失)
六、DQL 【重点】
DQL(Data Qeury Language 数据查询语言)
- 查询数据库数据,如 SELECT 语句
- 简单的单表查询或多表的复杂查询和嵌套查询
- 是数据库语言中最核心、最重要的语句
- 使用频率最高的语句
SELECT 语法
1 | SELECT [ALL | DISTINCT] |
注意 : [ ] 括号代表可选的 , { }括号代表必选得
1、简单查询语句
1 | -- 查询表中所有的数据列结果,但是效率低,不推荐 |
AS 子句作为别名
作用:
- 可给数据列取一个新别名
- 可给表取一个新别名
- 可把经计算或总结的结果用另一个新名称来代替
1 | -- 为列和表取别名 |
DISTINCT 去重
作用:去掉 SELECT 查询返回的记录结果中重复的记录(返回所有列的值都相同)
1 | -- 查看哪儿些同学参加了考试 |
表达式
数据库中的表达式一般由文本值,列值,NULL,函数和操作符等组成。
应用场景:
- SELECT 语句返回结果列中使用
- SELECT 语句中的 ORDER BY,HAVING 等子句中使用
- DML 语句中的 where 条件语句中使用表达式
1 | -- 查询自增步长 |
2、where 条件语句
作用:用于检索数据库中符合条件的记录。
搜索条件可由一个或多个逻辑表达式组成,结果一般为真或假。
逻辑操作符
| 逻辑操作符 | 语法 | 描述 |
|---|---|---|
| AND 或 && | a AND b 或 a && b | 逻辑与,同时为真结果才为真 |
| OR 或 || | a OR b 或 a || b | 逻辑或,只要一个为真,则结果为真 |
| NOT 或 ! | NOT a 或 !a | 逻辑非,若操作数为假,则结果为真 |
比较运算符
| 比较运算符 | 描述 | 实例 |
|---|---|---|
| = | 等号,检测两个值是否相等,如果相等返回true | (A = B) 返回false。 |
| <>, != | 不等于,检测两个值是否相等,如果不相等返回true | (A != B) 返回 true。 |
| > | 大于号,检测左边的值是否大于右边的值, 如果左边的值大于右边的值返回true | (A > B) 返回false。 |
| < | 小于号,检测左边的值是否小于右边的值, 如果左边的值小于右边的值返回true | (A < B) 返回 true。 |
| >= | 大于等于号,检测左边的值是否大于或等于右边的值, 如果左边的值大于或等于右边的值返回true | (A >= B) 返回false。 |
| <= | 小于等于号,检测左边的值是否小于或等于右边的值, 如果左边的值小于或等于右边的值返回true | (A <= B) 返回 true。 |
注意:<> 和 != 都是不等于的意思。
1 | -- 查询考试成绩区间在[95, 100] |
3、模糊查询
| 操作符名称 | 语法 | 描述 |
|---|---|---|
| IS NULL | a IS NULL | 若操作符为 NULL,则结果为真 |
| IS NOT NULL | a IS NOT NULL | 若操作符不为 NULL,则结果为真 |
| BETWEEN | a BETWEEN b AND c | 若 a 范围在 b 与 c 之间,则结果为真 |
| LIKE | a LIKE b | SQL 模式匹配,若a 匹配 b,则结果为真 |
| IN | a IN(a1, a2, a3, ……) | 若 a 等于 a1,a2…… 中的某一个,则结果为真 |
注意:
- 数据数据类型的记录之间才能进行算术运算
- 相同数据类型的数据之间才能进行比较
1 | -- ============================================= |
踩雷
- 没有
a = NULL这种写法,必须写成a IS NULL - 空字符串即**``**,并不等于 NULL
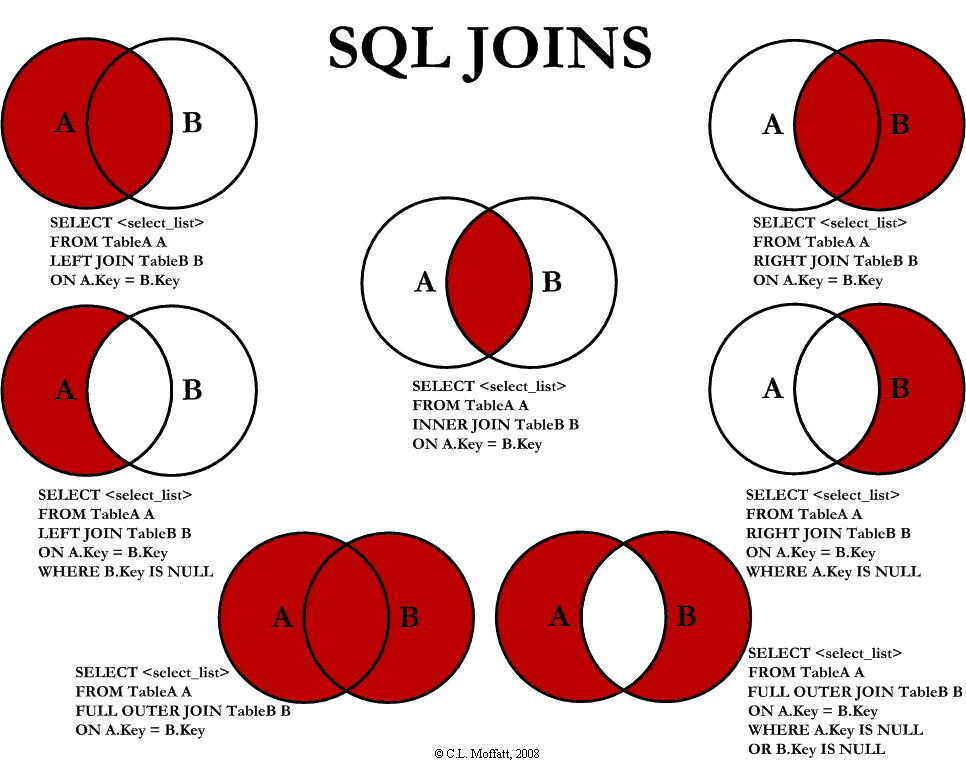
4、连接查询
Join
| 操作符名称 | 描述 |
|---|---|
| INNER JOIN | 如果左右表都匹配到,则返回行 |
| LEFT JOIN | 即使右表中没有匹配,也从左表中返回所有的行 |
| RIGHT JOIN | 即使左边中没有匹配,也从右表中返回所有的行 |
1 | /* |
加强练习
1 | -- 查询参加了考试的同学信息(学号,学生姓名,科目名,分数) |
WHERE 不能写在两个 JOIN 语句之间,要放在后面!详情请看这节开头的 SELECT 语法
5、自查询
顾名思义,即数据表与自身进行连接。
1 | -- 创建一个表 |
1 | -- 编写SQL语句,将栏目的父子关系呈现出来 (父栏目名称,子栏目名称) |
6、排序和分页
ORDER BY
- 用于根据指定的列对结果集进行排序
- 默认按照
ASC升序进行排序 - 如果需要进行降序排序,可以使用 DESC 关键字
LIMIT
1 | 语法:SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset |
- 第一个参数指定第一个返回记录行的偏移量,注意从
0开始 - 第二个参数指定返回记录行的最大数目
- 如果只给定一个参数:它表示返回最大的记录行数目
- 第二个参数为 -1 表示检索从某一个偏移量到记录集的结束所有的记录行
- 初始记录行的偏移量是 0(而不是 1)
分页优点:
- 用户体验
- 网络传输
- 查询压力
1 | -- 查询 数据库结构-1 的所有考试结果(学号 学生姓名 科目名称 成绩) |
7、子查询
子查询就是在查询语句的 WHERE 条件子句中,又嵌套了另一个查询语句,嵌套查询可由多个子查询组成,求解的方式是由里及外。子查询返回的结果一般都是集合,故而建议使用 IN 关键字。
1 | -- 查询 Java程序设计-1 的所有考试结果(学号,科目编号,成绩),并且成绩降序排列 |
8、分组查询
1 | -- 查询不同课程的课程编号,课程名称,平均分(大于60),最高分,最低分 |
WHERE 必须写在 GROUP BY 前面,分组后筛选要使用 HAVING,因为 HAVING 是根据前面筛选的字段再筛选,而 WHERE 是根据数据表中的字段直接进行筛选。
七、MySQL 函数
1、没那么常用的常用函数
数据函数
1 | SELECT ABS(-8); /*绝对值*/ |
字符串函数
1 | SELECT CHAR_LENGTH('狂神说坚持就能成功'); /*返回字符串包含的字符数*/ |
日期和时间函数
1 | SELECT CURRENT_DATE(); /*获取当前日期*/ |
系统信息函数
1 | SELECT VERSION(); /*版本*/ |
2、聚合函数
| 函数名称 | 描述 |
|---|---|
| COUNT() | 返回满足Select条件的记录总和数,如 select count(*) |
| SUM() | 返回数字字段或表达式列作统计,返回一列的总和。 |
| AVG() | 通常为数值字段或表达列作统计,返回一列的平均值 |
| MAX() | 可以为数值字段,字符字段或表达式列作统计,返回最大的值。 |
| MIN() | 可以为数值字段,字符字段或表达式列作统计,返回最小的值。 |
COUNT
以下三种统计表行数的方法,返回的结果都是一致的,那么有什么区别呢?
1 | SELECT COUNT(studentno) FROM student |
- COUNT(ColumnName)
- 查询某一字段的记录数,会忽略掉为 NULL 的记录。
- 如果上面查询的是 sex 列,就会发现记录数只有两条。
- COUNT(*)
- 因为是 SQL92 定义的标准统计行数的语法,因此 MySQL 对他进行了很多优化。
- MyISAM 会将表的总行数单独记录下来供
COUNT(*)查询。 - InnoDB 会在扫表的时候选择最小的索引来降低成本。
- 上述两个引擎优化的前提是没有进行 WHERE 和 GROUP 的条件查询。
在 InnoDB 中 COUNT(*) 和 COUNT(1) 实现上没有区别,而且效率一样,但是 COUNT(字段) 需要进行字段的非 NULL 判断,所以效率会低一些。
因为 COUNT(*) 是 SQL92 定义的标准统计行数的语法,并且效率高,所以请直接使用 COUNT(*) 查询表的行数!
练习
1 | -- 总和 |
3、MD5加密
MD5即Message-Digest Algorithm 5(信息-摘要算法5),用于确保信息传输完整一致。是计算机广泛使用的杂凑算法之一(又译摘要算法、哈希算法),主流编程语言普遍已有MD5实现。将数据(如汉字)运算为另一固定长度值,是杂凑算法的基础原理,MD5的前身有MD2、MD3和MD4。
实现数据加密
新建一个测试表
1 | CREATE TABLE `testmd5` ( |
插入数据
1 | INSERT INTO testmd5 VALUES(1,'yqx','123456'),(2,'yqx','456789') |
加密
1 | update testmd5 set pwd = md5(pwd); |
或者在插入数据时加密
1 | INSERT INTO testmd5 VALUES(3,'yqx3',md5('123456')); |
用户登录(将用户输入的密码加密后与数据库的密码进行比对)
1 | SELECT * FROM testmd5 WHERE `name`='yqx' AND pwd=MD5('123456'); |
4、小结
1 | -- ================ 内置函数 ================ |
八、事务(transaction)
1、ACID 原则
原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency)
一致性是指事务前后数据的完整性必须保持一致。
隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事物的操作数据所干扰,多个并发事物之间要相互隔离。
持久性(Durability)
持久性是指一个事物一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
接下来举例进行说明。
原子性
针对同一个事务
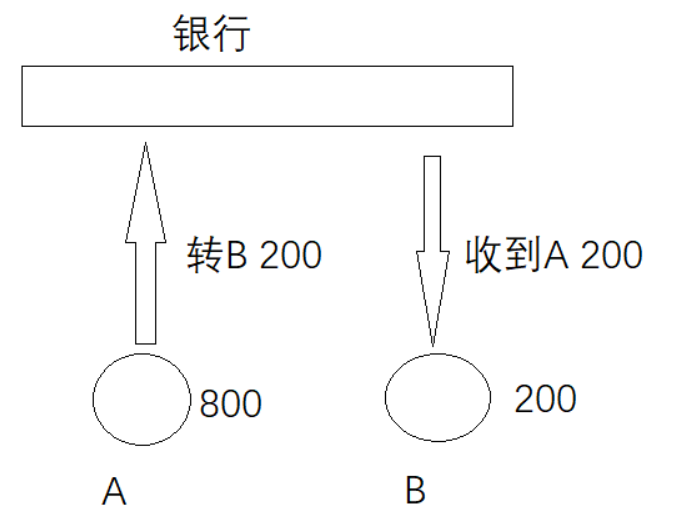
在个过程包含两个步骤
A:800 - 200 = 600
B:200 + 200 = 400
原子性表示,这两个步骤要么一起成功,要么一起失败,不可能 A 的钱扣掉了,而 B 却没有收到钱。
一致性
针对一个事物操作前与操作后的状态一致
操作前A:800,B:200
操作后A:600,B:400
一致性表示事务完成后,符合逻辑运算(A + B = 1000)
持久性
表示事务结束后的数据不随着外界原因导致数据丢失
操作前A:800,B:200
操作后A:600,B:400
如果在操作前(事务还没有提交)服务器宕机或者断电,那么重启数据库以后,数据状态应该为
A:800,B:200
如果在操作后(事务已经提交)服务器宕机或者断电,那么重启数据库以后,数据状态应该为
A:600,B:400
隔离性
针对多个用户同时操作,主要是排除其他事务对本次事务的影响
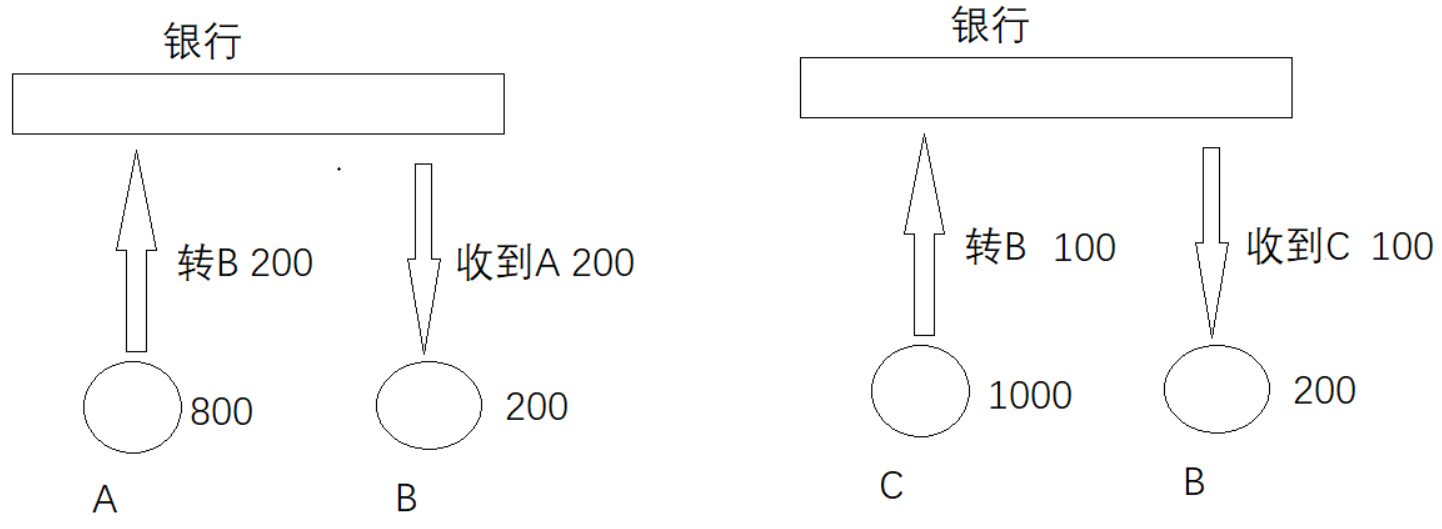
事务一)C向B转账100
事务二)A向B转账200
两个事务同时进行,其中一个事务读取到另外一个事务还没有提交的数据。
例如 C 先给 B 转100元,在事务还没有提交之前,A 给 B 转了200元,而此时数据库中 B 的金额仍然是 200 元。待 C 给 B 的事务完成后,A 也完成了他的事务,此时数据库中 B 的金额将会是后手事务二提交的,也就是200 + 200 = 400,直接少了100元。
隔离性用于解决以上问题。
2、隔离级别
脏读:
指一个事务读取到另一个事务未提交的数据。(具体查看上面的隔离性)
不可重复读:
在一个事务内读取表中的某一行数据,多次读取结果不同。(这个不一定是错误,只是某些场合不对)
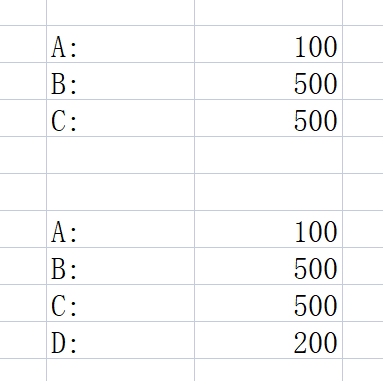
页面统计查询值

生成报表时,有人又转给 B 300 元
虚读:
是指在一个事务内读取到了别的事务插入的数据,导致前后读取数量总量不一致。
(一般是行影响,如下图所示:多了一行)
四种隔离级别设置
数据库
set transaction isolation level 设置事务隔离级别
select @@tx_isolation 查询当前事务隔离级别
| 设置 | 描述 |
|---|---|
| Serializable | 可避免脏读、不可重复读、虚读的发生。(串行化) |
| Repeatable read | 可避免脏读、不可重复读情况的发生。(可重复读) |
| Repeatable read | 可避免脏读情况发生。(读已提交) |
| Read uncommitted | 最低级别,以上情况均无法保证。(读未提交) |
java
适当的 Connection 方法,比如 setAutoCommit 或 setTransactionIsolation
| 设置 | 描述 |
|---|---|
| TRANSACTION_SERIALIZABLE | 指示不可以发生脏读、不可重复读和虚读的常量。 |
| TRANSACTION_REPEATABLE_READ | 指示不可以发生脏读和不可重复读的常量;虚读可以发生。 |
| TRANSACTION_READ_UNCOMMITTED | 指示可以发生脏读 (dirty read)、不可重复读和虚读 (phantom read) 的常量。 |
| TRANSACTION_READ_COMMITTED | 指示不可以发生脏读的常量;不可重复读和虚读可以发生。 |
3、基本语法
1 | -- 使用set语句来改变事务自动提交 |
4、测试
1 | /* |
九、索引
1、介绍
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。说起加速查询,就不得不提到索引了。
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。
索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
索引的作用
- 提高查询速度
- 确保数据的唯一性
- 可以加速表和表之间的连接 , 实现表与表之间的参照完整性
- 使用分组和排序子句进行数据检索时 , 可以显著减少分组和排序的时间
- 全文检索字段进行搜索优化.
分类
- 主键索引 (Primary Key)
- 唯一索引 (Unique)
- 常规索引 (Index)
- 全文索引 (FullText)
2、各索引区别
主键索引
- 最常见的索引类型
- 确保数据记录的唯一性
- 确定特定数据记录在数据库中的位置
- 一张表只能有一个主键索引
不唯一的唯一索引
- 避免同一个表中某数据列的值重复
- 一张表可以有多个唯一索引
常规索引
- 快速定位特定数据
- index 和 key 关键字都可以设置常规索引
- 应加在需要查询的字段
- 不宜添加太多常规索引,会影响数据增删改的效率,因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
全文索引
百度搜索
快速定位特定数据
只能用于 MyISAM 类型的数据表(INNODB 在 MySQL 5.6 之后也支持全文索引)
只能用于 CHAR,VARCHAR,TEXT 等文本类型数据
适合大型数据集
建立索引会占用磁盘空间的索引文件。
1 | -- 方法一:建表时 |
3、测试各索引性能
建立测试表
1 | CREATE TABLE `app_user` ( |
插入100W 测试数据
1 | DROP FUNCTION IF EXISTS mock_data; |
测试结果
每个索引效率都差不多,会比没有索引快十倍,创建索引的时候会耗点时间。
1 | -- 无索引 |
4、小结
索引准则
- 索引不是越多越好
- 不要对经常变动的数据加索引
- 小数据量的表建议不要加索引
- 索引一般应加在查找条件的字段
索引的数据结构
我们在创建上述索引的时候,可以为其指定索引类型
- hash 类型的索引:查询单条快,范围查询慢
- btree 类型的索引:b+ 数,层数越多,数据量呈指数级增长(INNODB 默认)
不同的存储引擎支持的索引类型也不一样
- INNODB 支持事务,支持行级别锁定,支持 B-tree、Full-Text 等索引,不支持 Hash 索引。
- MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-Text等索引,不支持 Hash 索引。
- Memory 不支持事务,支持表级别锁定,支持B-tree、Hash 等索引,不支持 Full-Text 索引。
- NDB 支持事务,支持行级别锁定,支持 Hash 索引,不支持 B-tree、Full-Text 等索引。
- Archive 不支持事务,支持表级别锁定,不支持 B-tree、Hash、Full-text 等索引。
参考文章:CodingLabs - MySQL索引背后的数据结构及算法原理
十、权限管理和备份
1、权限管理
1 | /* 用户和权限管理 */ |
权限解释
1 | -- 权限列表 |
2、MySQL 备份
数据备份的重要性
- 保证重要数据不丢失
- 数据转移
MySQL 数据库备份方法
- 数据库管理工具,如 SQLyog
- 直接拷贝数据库物理文件(/data/*)
- 使用命令行,mysqldump
1 | -- 导出 |
十一、规范化数据库设计
1、为什么需要数据库设计
当数据库比较复杂时我们需要设计数据库
糟糕的数据库设计 :
- 数据冗余,存储空间浪费
- 数据更新和插入的异常
- 程序性能差
良好的数据库设计 :
- 节省数据的存储空间
- 能够保证数据的完整性
- 方便进行数据库应用系统的开发
软件项目开发周期中数据库设计 :
- 需求分析阶段:分析客户的业务和数据处理需求。
- 概要设计阶段:设计数据库的E-R模型图 , 确认需求信息的正确和完整。
设计数据库步骤
- 收集信息,与该系统有关人员进行交流 , 座谈 , 充分了解用户需求 , 理解数据库需要完成的任务。
- 标识数据库要管理的关键对象或实体,实体一般是名词。
- 标识每个实体需要存储的详细信息。
- 标识实体之间的关系。
2、三大范式
问题 : 为什么需要数据规范化?
不合规范的表设计会导致的问题:
信息重复
更新异常
插入异常
- 无法正确表示信息
删除异常
- 丢失有效信息
第一范式 (1st NF)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
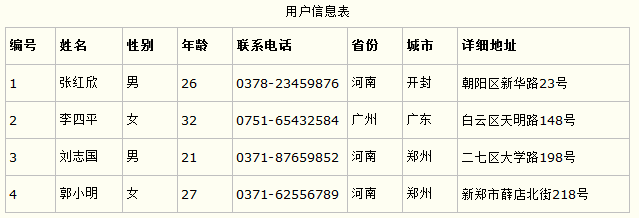
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,如下表所示。
第二范式(2nd NF)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键,如下表所示。
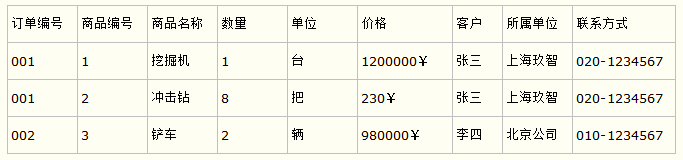
这样就产生一个问题:这个表中是以订单编号和商品编号作为联合主键。这样在该表中商品名称、单位、商品价格等信息不与该表的主键相关,而仅仅是与商品编号相关。所以在这里违反了第二范式的设计原则。
而如果把这个订单信息表进行拆分,把商品信息分离到另一个表中,把订单项目表也分离到另一个表中,就非常完美了。如下所示。
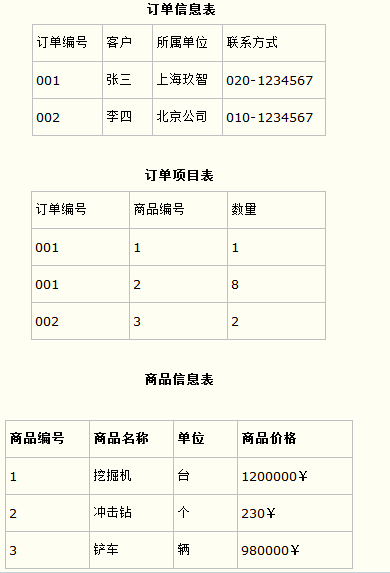
这样设计,在很大程度上减小了数据库的冗余。如果要获取订单的商品信息,使用商品编号到商品信息表中查询即可。
第三范式(3rd NF)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。如下面这两个表所示的设计就是一个满足第三范式的数据库表。
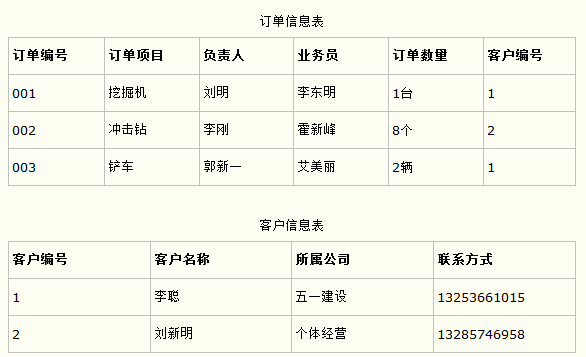
这样在查询订单信息的时候,就可以使用客户编号来引用客户信息表中的记录,也不必在订单信息表中多次输入客户信息的内容,减小了数据冗余。
但很多时候我们会为了性能而抛弃这些规范化的操作,因为一个复杂的表如果按照三大范式来设计,很有可能会拆成十多个表,这样在数据库查询时会十分影响效率(多表查询)。
规范化和性能的关系
为满足某种商业目标 , 数据库性能比规范化数据库更重要
在数据规范化的同时 , 要综合考虑数据库的性能
通过在给定的表中添加额外的字段,以大量减少需要从中搜索信息所需的时间
通过在给定的表中插入计算列,以方便查询