1、网格搜索
1.1、什么是网格搜索?
在 过拟合和欠拟合 中,我们是手动调整超参数 degree ,经由人工一一比对来获取最好的值,效率比较低下。因此我们引入网格搜索这个概念,不要被这个看起来很高大上的名词吓唬住了,其实逻辑十分简单,具体请看下述代码。
使用 sklearn 中自带的波士顿房产数据作为我们的测试数据。
1 | import sklearn |
这里我们要网格搜索的参数即为 p,neighbor, weight。
可以看到所谓 网格搜索 就是使用 for-loop 像网格一样将你预设的可能的值都遍历一遍,依次寻求 score 最高的超参数组合。
1 | KNN中的超参数: |
1 | weights = ["uniform", "distance"] |
输出结果如下。
1 | best_weight = distance |
注:KNeighborsRegressor 和 KNeighborsClassifier 思想相同。
KNeighborsClassifier 是找到附近 k 个数据,找到最多那个类别作为预测的类别,用于解决分类问题。
而 KNeighborsRegressor 是找到附近 k 个数据,然后取平均值作为预测的数值,用于解决回归问题。
1.2、scikit 中的实现
1 | from sklearn.model_selection import GridSearchCV |
GridSearchCV 使用交叉验证来训练数据,即 train-validation-test。因此best_score_可能会比较低。
1 | grid_search.best_params_ = {'n_neighbors': 5, 'p': 1, 'weights': 'distance'} |
2、交叉验证
在之前模型的训练中,我们都是以测试数据集的 score 来衡量模型的好坏,换言之就是根据 test_score 来调整超参数,并从所有的模型中挑出 test_score 最高的作为我们的预测模型。但这样也会暴露出一个问题,在模型训练期间,我们的模型就已经见过了测试数据集,因此可能会过拟合测试数据集!
这样肯定是不对的,要模拟真正的生产环境,那么测试数据集就不能参与到模型的训练当中。我们只需要再引入一个验证数据集来代替之前测试数据集的作用就行了。
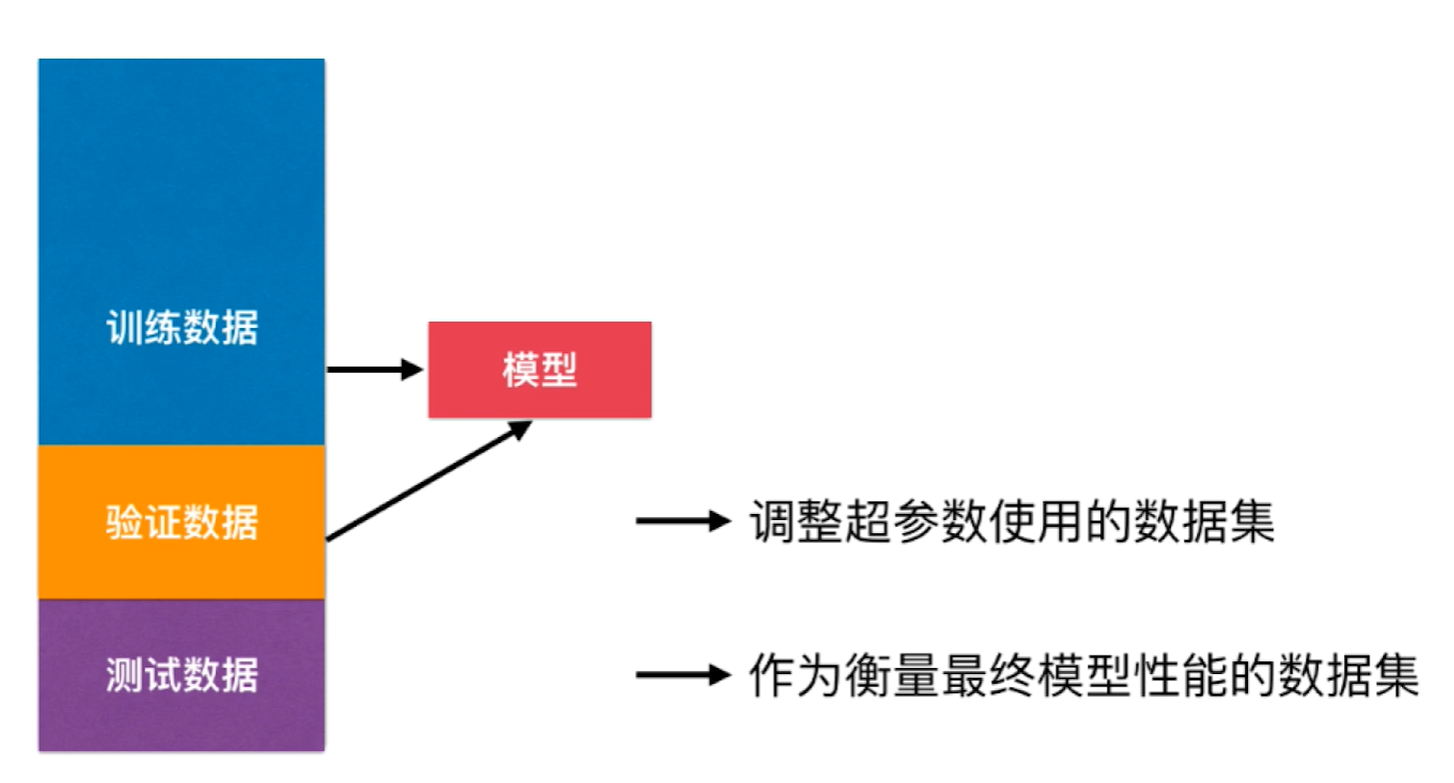
但其实这样也会有过拟合验证数据集的问题,因此就有了交叉验证。具体则是将训练数据集分成 K 份,从这 K 份当中选择一份作为验证数据集,其余 K-1 份作为训练数据集。一共有 $C^1_K = K$ 种分法,因此我们可以得到 K 个模型,因此这也被称为 K-folds Cross Validation(K折交叉验证),最后取他们在验证数据集上的均值作为判断模型好坏的依据。
这里提一句,在 scikit-learn 的网格搜索中,默认使用的是 cv = 5 的交叉验证,也就是五折交叉验证。

当交叉验证的 K = n_samples 时,会产生 n_samples 个模型,这时训练出来的模型完全不受随机的影响,将最接近模型真正的性能指标,代价就是训练时间会扩大 n_samples 倍,这就是 LOO-CV(Leave One Out Cross Validtion),也就是留一法。
2.2、代码实现
1 | # 将第i份作为验证集 |