引入
继之前的多项式回归,如果 degree 设置过大或者过小会出现什么样的问题呢?
在此之前,先来说明一下 归一化 的必要性。多项式回归采用了特征组合的方式,当 degree 为100时,最高次就是100次,而最低次只是常数级,各个维度数值之间的跨度非常大,这就导致 eta 必须设置得非常小,否则稍大一点,就会无法拟合,变成 nan 。
当 degree 为10时, eta就必须设置成$10^{-19}$,很不利于我们训练模型,所以在数据与距离阶段除了要多项式化还得归一化!
根据上述要求,改进了一下多项式回归的类。
1 | class PolynomialRegression: |
当然直接使用 sklearn 中的 Pipeline 可以更加简便的实现这一切。
Pipeline 具体运作机制就是逐行运行,上一行的输出就是下一行的输入,因此我们先进行多项式化,再归一化,最后放入线性回归中训练模型。
1 | from sklearn.pipeline import Pipeline |
数据拟合
先写一个绘制拟合曲线的函数便于我们观测结果。
1 | def plot_matching_curve(X, y, degree, eta = 1e-6, n_iters = 1e5): |
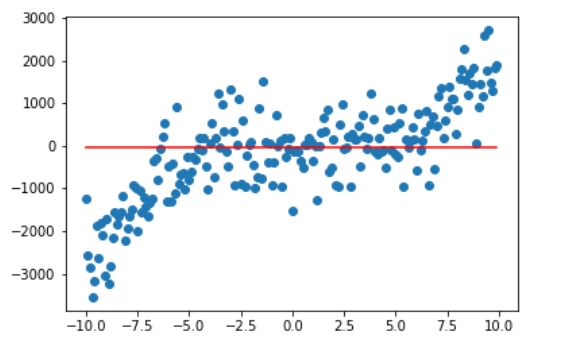
当 degree 为0时,也就是最高次为0次,拟合曲线成一条直线,这就是欠拟合。
毕竟函数只有一个常数嘛,合理。
1 | plot_matching_curve(x.reshape([-1, 1]), y, 0) |
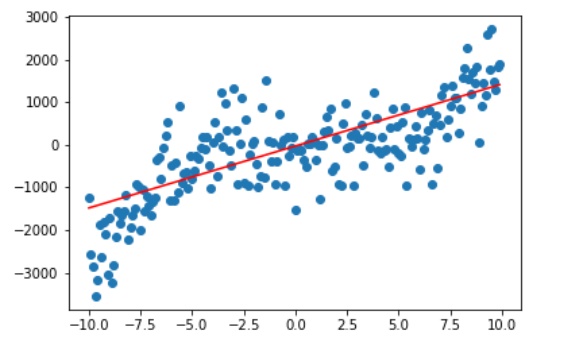
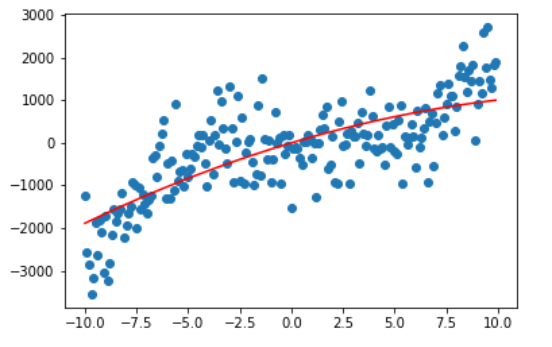
再来看看 degree 分别为1,2的情况,是不是越来越接近我们的拟合曲线了。
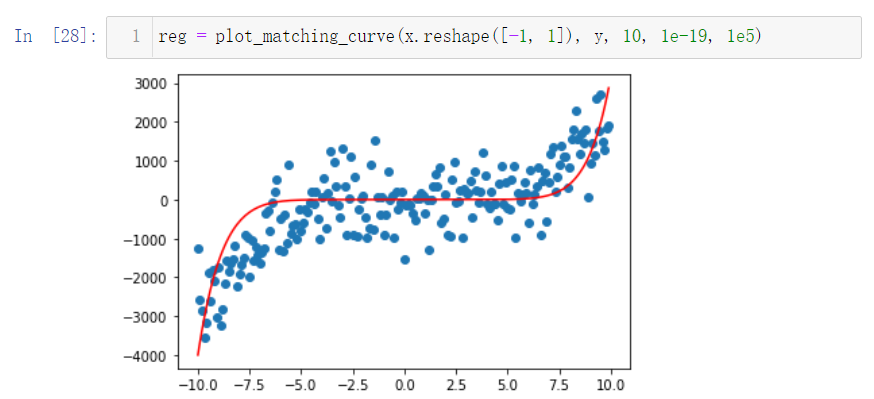
当 degree 为3时,曲线终于拟合了我们的数据。
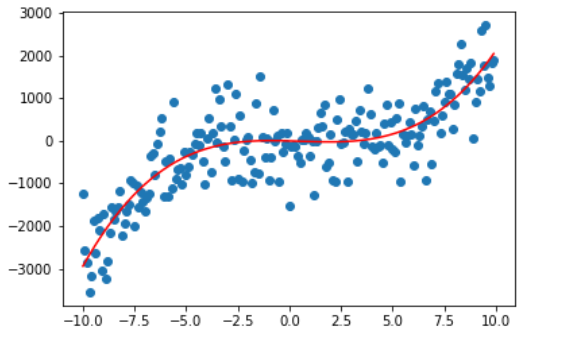
那我们再看看 degree 为10,50,100,200的情况。
很容易可以观察出,曲线变得越来越复杂,也越来越能拟合我们的训练数据,这是因为随着 degree 的增大,参数数量的增长使得我们的模型可以将训练的数据给记住,但这真的是我们想要的吗?
不,我们想要的是泛化能力,是在测试数据乃至之后模型上线后的真实数据上也能有非常好的预测能力。
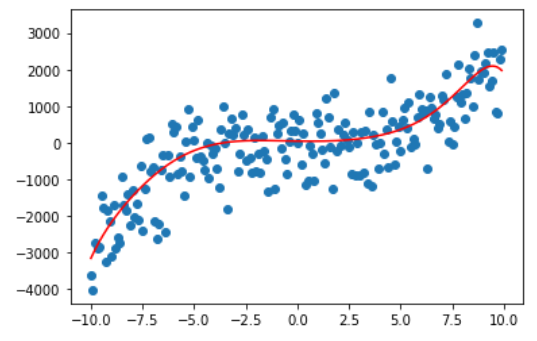
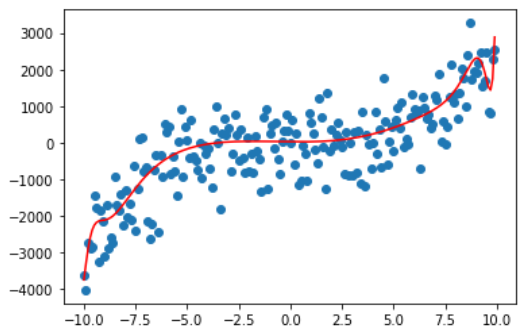
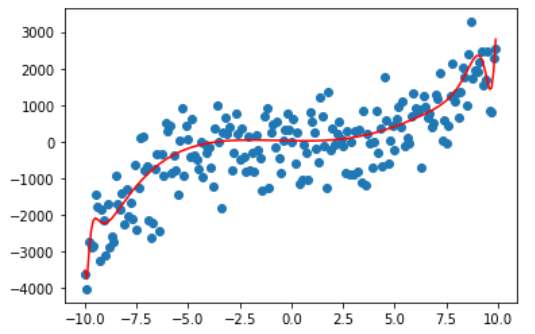
之前也说过了,多项式化是阶乘式地增长,一旦 degree 过大,直接就会导致栈溢出。

学习曲线
通过观察学习曲线,也可以帮助我们判断出模型是否有过拟合或欠拟合的情况。它是绘制模型在训练集和测试集上的性能函数。
1 | from sklearn.model_selection import train_test_split |
这次我们把目标函数换成二次函数。
1 | X = np.random.uniform(-3,3,size=100).reshape(-1,1) |
degree = 1
随着样本数量的增加 test 的误差在减小,train 的误差在增加,而当样本到了一定程度后,两者也没有保持在一个较小的程度上。这时说明模型欠拟合。
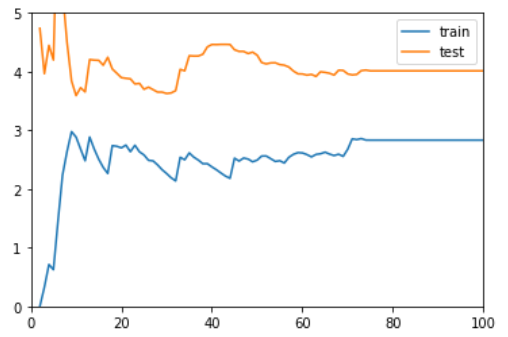
degree = 2

随着样本数量的增加 test 的误差在减小,train 的误差在增加,而当样本到了一定程度后,两者基本持平,保持在一个较小的程度上。这时模型已经拟合。
degree = 10
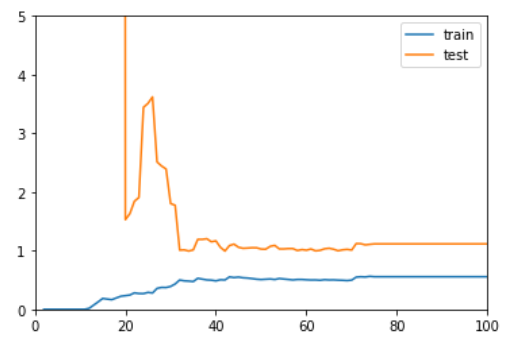
随着样本的增加 test 的误差在减小,train 的误差在增加,但当样本到了一定程度后,在 train 上的误差要比在 test 上的误差小得多,这时就要注意是不是过拟合了。
degree = 100
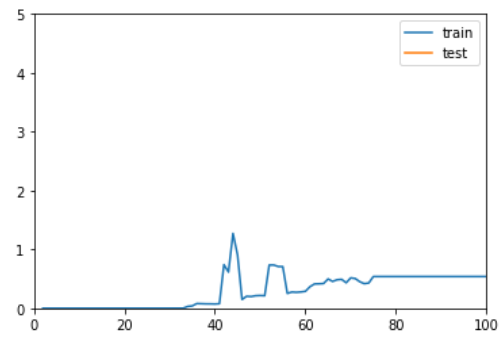
此时 test 上的误差已经飙到天上去了,妥妥的过拟合。
总结
在训练数据集上表现良好,却在测试数据集上表现差劲的就是过拟合,这时候要降低参数数量。
而在训练数据集上表现就不尽人意的有可能是欠拟合(也有可能是模型压根不对等问题),这时候可以试试增大模型,增加参数数量。